CopernNet : Point Cloud Segmentation using ActiveSampling Transformers
In the dynamic field of railway maintenance, accurate data is critical. From ensuring the health of ...


Published on: August 19, 2022
Now that we have chosen the right algorithm for our machine learning problem, and we have collected and prepared a dataset, we can finally start training our network to obtain a model that will solve our problem. But the training depends on many parameters that are hard to choose. Let’s take a look at the most important ones and discuss strategies that can be used to intelligently manage your experiments.
In deep learning, we look for the set of network parameters (weights) resulting in the best score for our task. The network architecture determines how many parameters we have and how they depend on each other (model depth, width and topology). But we also need to define how we update these parameters during training as well as to provide a quantitative score function. These control parameters are often called hyperparameters. They affect the speed and quality of the learning process. Let’s discuss a few of the most important hyperparameters.
The network weights are found using an iterative optimization procedure that minimizes an objective function called the loss function. The loss function must well represent the problem that the algorithm is trying to solve, otherwise the training will never achieve its goal. Examples of good loss function choice are cross-entropy function for classification, mean squared error for regression or dice coefficient for segmentations. One can consult the literature on whether there are variants of loss functions for specific tasks: object detection, semantic segmentation.
The choice of possible optimization algorithms includes SDG, Adam or RProp. The algorithm updates the model weights according to the learning rate. A good learning rate is a trade-off between slow convergence and overshooting. If the learning rate is too small, training will take a very long time. If it is too large, the network will be driven far away from the minimum and might even diverge. Practically, a good learning rate range can be found using the following pre-training procedure.
Split your training set into mini batches and load them into your neural network one by one, varying the learning rate over a wide range of values (10-7-100). You can then plot the loss function as a function of the learning rate, which should decrease as we increase the learning rate and then reach a minimum (see the illustration). The learning rate interval corresponding to the area where the loss function decreases is a good range for your learning rate.
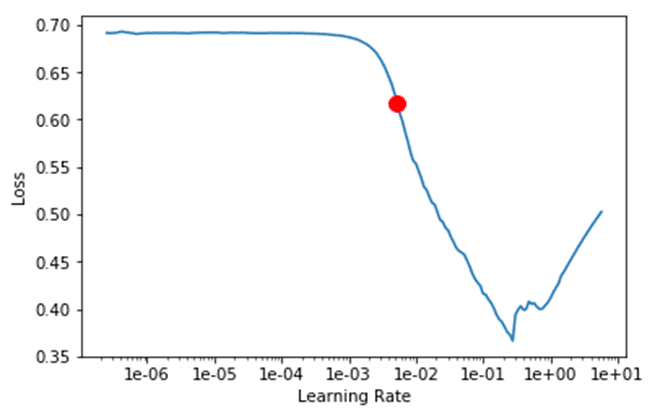
It is recommended to use a variable learning rate in training instead of a fixed value. A good learning rate scheduler is usually a function that grows in the beginning and then drops down. Using a cyclic scheduler with the learning rate continuously oscillating in between the minimum and maximum bounds allows to avoid the problem of saddle points in the optimization.
There are many more hyperparameters than the choice of optimization algorithm, loss function, and learning rate scheduler. Often these hyperparameters are algorithm or network specific. But how to choose the optimal set of these parameters?
As a starting point, it is recommended to first experiment with the hyperparameters that can be found in the literature. The authors have already experimented with the settings, and the best values are published. In general, the optimal set of hyperparameters can be found using a certain search strategy.
In grid search strategy, we divide the domain into a discrete grid and then try every combination of values from the grid. In a random search strategy, we pick up random hyperparameter combinations instead of exploring all possibilities from the grid. Eventually, more advanced Bayesian methods of hyperparameter search can be employed.
When training your network or looking for the optimal set of hyperparameters, It is very important to keep track of all your experiments to make sure they are repeatable. Logging your experiments in a structured way enables you to discover patterns in parameter effectiveness and make smart choices for the next experiment. They can also be used to transfer knowledge to other people about what has already been tried or to report progress.
TensorBoard is the visualizer of the TensorFlow framework that contains functionalities to save parameters and compare trained networks. For example, one can track the loss function and metrics evolution, quantify the computational performance of the model and display the images with predictions. The open source MLflow platform is agnostic of the underlying environment and contains some extra functionalities.
In this article, we discussed which control parameters govern the training of neural networks, as well as possible strategies for finding the optimal set of these parameters and tracking of experiments. In our next article, we will discuss what to do if something goes wrong while training the network, how to debug your network and prepare the final model for deployment.
Subscribe to our newsletter and stay up to date.
