RINF 2026: What Railway Infrastructure Managers Need to Know
Visit our dedicated RINF roadmap site: roadmap2rinf.eu The European railway infrastructu ...
Published on: February 9, 2022
The recent advances in machine learning have given computer vision algorithms the ability to perform tasks with ever increasing speed and accuracy. But with a growing number of machine learning techniques, it can be hard to figure out which algorithm will deliver the best results. Will you go for a traditional machine learning algorithm or do you need a deep learning network to accomplish your computer vision task? Let’s have a look at the possibilities.
But first, the basics. What is machine learning, and what is the difference with deep learning? We could define it as follows:
Let’s have a look at the pros and cons of both types of machine learning.
In traditional machine learning, there usually is a manual (human) process of feature engineering. This is the process of transforming raw data into numerical features that can be processed while preserving the information in the original data set. Efficient feature engineering is not an easy task and might be even more important than the choice of the algorithm itself. The input data for traditional algorithms must be presented in a structured way, in tabular or vector representations.
Traditional machine learning makes sense when:
Traditional algorithms can perform classification and regression tasks, but fail for more complicated ones, such as multiple object detection, object segmentation or object tracking in video. Most of the state-of-the-art traditional algorithms are implemented in the scikit-learn library, a free machine learning library for Python.

As you might have noticed, some of the algorithms can perform both tasks, but require different training targets (“loss functions”). Spoiler alert: we have an article coming up on traditional machine learning algorithms for machine vision that will give you more details about these algorithms.
Modern machine learning algorithms have advanced significantly, benefiting from improvements in computing power, memory capacity, and optics performance. Deep learning is probably one of the most impressive examples. Compared to traditional computer vision algorithms, deep learning makes it possible to achieve greater accuracy in extremely complex tasks such as image classification, object detection, semantic segmentation, and Simultaneous Localization and Mapping (SLAM).
In contrast to traditional machine learning, deep learning does not need human intervention for feature engineering. Instead, deep learning algorithms learn all transformations by themselves by working directly with the source data (images and video). This is one of the reasons why deep learning is very popular in computer vision applications. New research and network architectures are being published continuously.
So, which deep learning algorithm do you need for your computer vision task? Let’s look at the possibilities for some of the most common industrial problems:
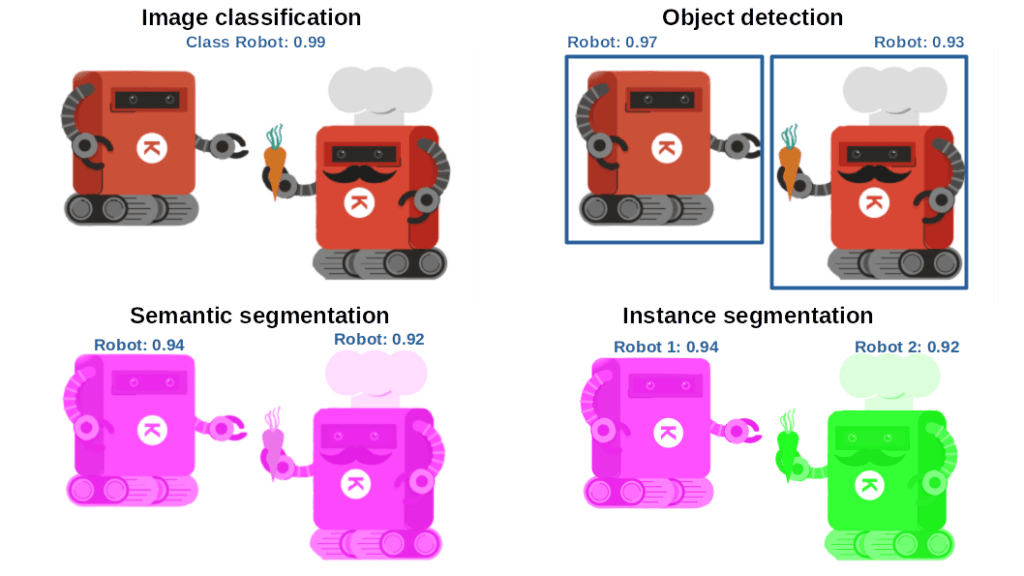
Spoiler alert: we have an article coming up on best practices for employing a deep learning algorithm for industrial applications, which will give you more insights into how to achieve the best performance for your algorithm.
There is such a wealth of machine learning algorithms out there, that choosing the right algorithm for your computer vision application can feel overwhelming. Especially in the area of deep learning, the industry has seen great improvements. But the question whether you need a traditional machine learning algorithm or a deep learning technique can only be answered based on the type of problem you want to solve and on the results you expect to achieve. In this article, we have briefly discussed the difference between traditional algorithms and deep learning, but if you’re still not sure which approach you need to follow, there’s definitely a Kapernikov expert who can help you decide.