CopernNet : Point Cloud Segmentation using ActiveSampling Transformers
In the dynamic field of railway maintenance, accurate data is critical. From ensuring the health of ...


Published on: May 25, 2022
Data is a key component of AI, artificial intelligence and machine learning. Without a good dataset, it is impossible to build a good model, no matter how complex your algorithm may be. In this blog post series, we will look at some of the best practices to keep in mind when working with data for your machine learning project. In this first article, we will cover the initial stages of any machine learning lifecycle, including collecting, annotating, and analyzing a dataset.
First, you can search for a similar problem dataset that is already publicly available. Having a good annotated dataset could save you a lot of time at the initial stage of the project. Foresee some time to inspect the quality of the dataset. In order to avoid legal issues, it is important to carefully review the license under which the dataset is distributed.
Often the only way out is to collect your own dataset. Your dataset should be representative, meaning the data the model is trained on should be similar to the data you have in production. The data collection phase in machine vision projects is a good time to think about how well positioned your camera is and to improve the visibility of the scene. Changing the camera angle or position at a later stage in production can significantly reduce the performance of the algorithm. This might imply additional effort to re-annotate the new dataset, resulting in significant costs.
The data collection phase in machine vision projects is a good time to think about how well positioned your camera is and to improve the visibility of the scene.
The size of the dataset depends on the complexity of the problem. In general, the more data you have, the better for your model. For realistic industrial cases, as an empirical rule, hundreds to thousands of images are enough.
Some types of data may be very scarce or expensive to collect. An alternative to real world data is synthetic (e.g., rendered) data. The production of synthetic data does not require manual labor for annotation. Moreover, the number of available images can be quasi infinite. Nevertheless, it is recommended to also collect a (limited) set of real images, for validation or finetuning.
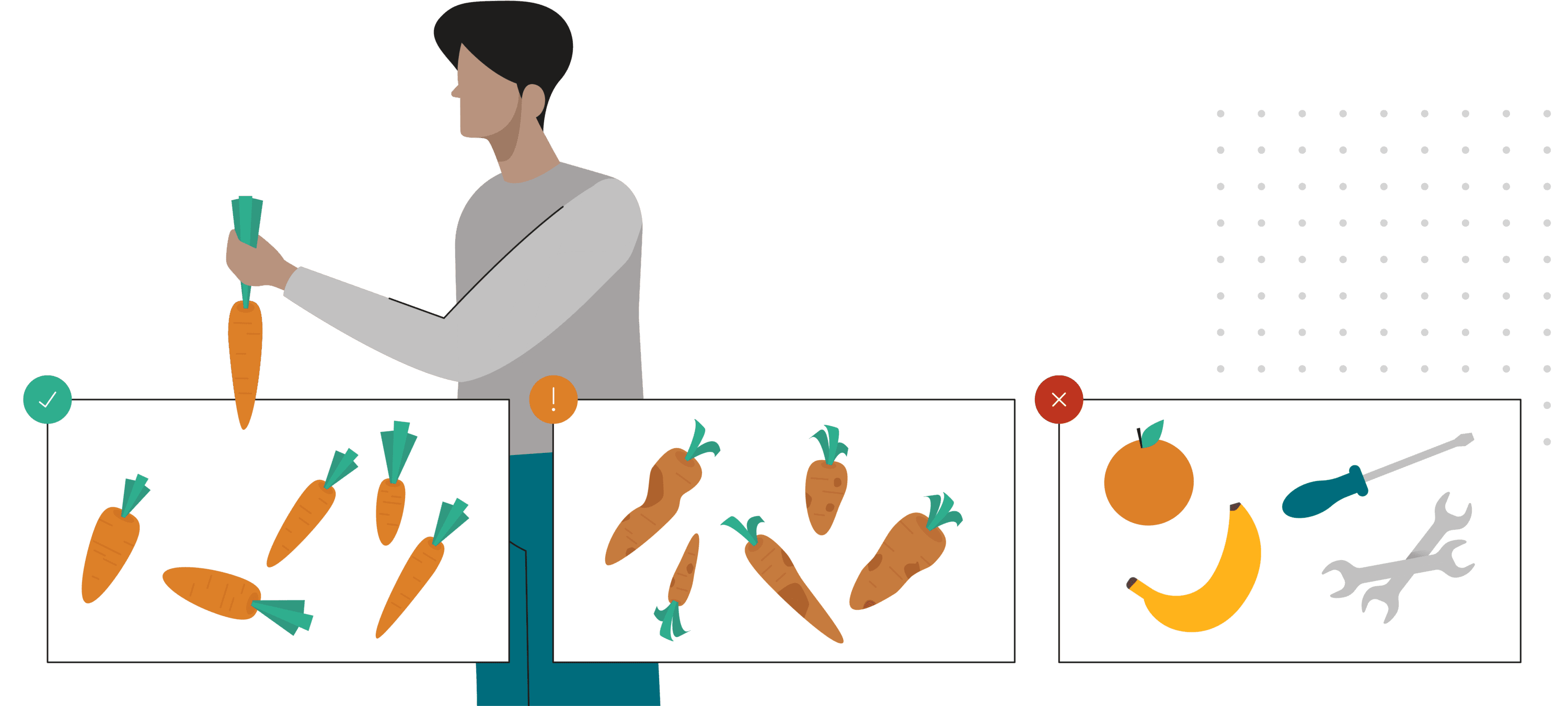
When using a supervised machine learning model, simply collecting plain data is not enough. The data should be annotated with ground truth annotations to guide the supervised training of your machine learning model. This annotation should be identical to the output you expect from the network: if you want object detection, you should specify bounding boxes, if you want segmentation, you need to annotate every pixel. It is also recommended to think upfront of all possible metadata that might be interesting, so you won’t have to reannotate.
Annotation is a very tedious task that requires significant human effort. Free annotation frameworks like CVAT or Labelme provide a convenient user interface and reduce the required number of clicks. On the other hand, commercial systems like hasty.ai, V7 Darwin or Roboflow have extra functionalities (super-pixel segmentation, automatic annotation proposals…) that can speed up the annotation process, but could be very expensive if data load is large. See the detailed guide for comparing annotation tools.Annotations that require specialized knowledge are best done by experts. Otherwise, if your data is not confidential, it might be interesting to check out Amazon Mechanical Turk. Here, the task is distributed over persons that perform annotations for a fee. If you go this way, make sure to build some redundant schemes to filter out the unreliable annotators. For instance, you could annotate a subset of images yourself and compare these with the output of Mechanical Turk. Another strategy is to allow multiple people to annotate the same images and check their consistency with a review.
Part of the annotation effort can be reduced using an active learning strategy. This involves iteratively training a model and using it to select the most relevant images to annotate next. The goal is to achieve comparable results with only a fraction of the annotation effort that comes with annotating images at random.
Active learning allows comparable results with only a fraction of the annotation effort, by interactively training a model and using it to select the most relevant image to annotate next.
When you finally collect and annotate your dataset, it’s time to analyze it. Analyzing a dataset helps you better understand your data by learning about underlying statistical patterns, find outliers and anomalies, and clean data up from bad or repeated images. For example, you can check how balanced your dataset is, and think about sampling techniques to deal with imbalance. Discovering image metadata and embedded feature vectors allows us to find the outliers. If you are using one of the traditional machine learning algorithms, you should engineer the features you are going to input into your algorithm.
Now, after the initial stages of collection, annotation and analysis, we can already pass our data to the neural network. In the next article, we will discuss some data practices that can help us improve the performance and reliability of the model as well as to track our experiments.
Subscribe to our newsletter and stay up to date.
