RINF 2026: What Railway Infrastructure Managers Need to Know
Visit our dedicated RINF roadmap site: roadmap2rinf.eu The European railway infrastructu ...
Published on: July 6, 2022
Data is a key component of machine learning. Without a good dataset, it is impossible to build a good model, no matter how complex your algorithm may be. In this blog post series, we will look at some of the best practices to keep in mind when working with data for your machine learning project. In Part 1, we discussed how to collect, annotate, and analyze a dataset. We now move on to a discussion of best practices that lead to better and more robust model training.

Machine learning algorithms should never be trained on all available data. Overwise, your algorithm will simply “remember” it, giving artificially high results on the data it has already seen, but failing on the new unfamiliar data in production. This situation is called overfitting. To avoid it, we must be able to estimate the performance of our model independently and reliably.
Having validation and test sets for evaluation helps us perform an unbiased hyperparameter search. The reasonable separation ratio is 60-20-20%, respectively. The data is usually randomly shuffled before splitting. However, it’s a good idea to keep the distribution of the entire set’s data in each subset so that each image category is present in equal proportions throughout.
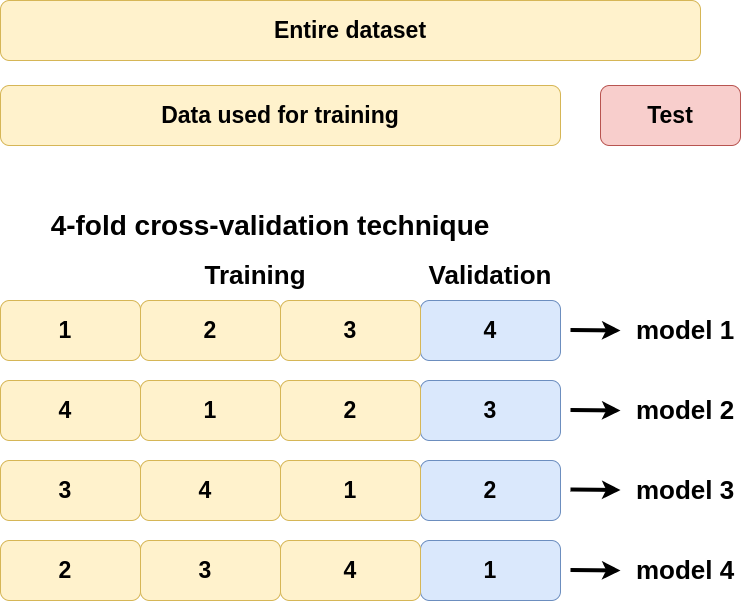
Another way to overcome biased or uneven data splitting is to use K-fold cross-validation splitting. In the cross-validation approach, we split our dataset K times (K = 3, 5, 10) into K different training and validation subsets. Further, our algorithm is trained on the data for each split, resulting in K different models tested on different validation sets.
By comparing the model performances, we can be more confident in our algorithm performance. For example, large variations in results between the folds is a sign of bad data distribution. For production, we should use the best model among the K folds.
If you want to increase the amount of data in your dataset, you don’t always have to collect new data. The first strategy you should think about is data augmentation. Data augmentation is the process of creating variants of input data from existing data samples and using them in the training phase. Some common forms of image augmentation are geometric transformations (mirroring, rotations, translations), cropping/zooming and changes in the contrast/brightness of images.

The key is to apply transformations that result in images that we could see in the original dataset. This will cause the training set to better represent the distribution of the data we want to learn. By performing data augmentation, we get more annotated data without the costly step of collecting and annotating additional data. The popular libraries for data augmentation are albumentations, imgaug and OpenCV packages.
During model development, our dataset is constantly changing. Importantly, a different dataset results in a different model. Thus, it is important to always be able to reconstruct the exact dataset that was used for an experiment, to ensure repeatability and ease of debugging. A data version control system (DVC) is a tool that allows you to keep track of the version of your dataset. Check out our article on DVC to know more about data version control.
In this small series of articles about data we have covered different stages of the data lifecycle from data collection and preparation to data processing and versioning. Following these guidelines will help you efficiently use data for your project, whether it’s a small personal project or a complex project for your business.