Interview with Frank Dekervel: Agentic AI, Applied
"Agentic AI turns the knowledge worker fro ...
Published on: June 23, 2021
In machine learning or deep learning, training a good model starts from the data that is fed into it. At Kapernikov we do a lot of computer vision on 2D images, in order to provide automation in an industrial setting. For many supervised learning tasks, such as segmentation, this means that we need high quality data accompanied by equally high quality annotations.
Using the right tools to annotate 2D images comes with the obvious benefit of faster annotation, but also rewards us with versatility, quality control and automation. All of this allows us to spend more time on constructing better models, while safeguarding the quality of input data. In this blog post, we sketch the landscape of annotation platforms, and more importantly – given the changing nature of these – what to look for when selecting one of them.

Every user has different requirements for their annotation platform, depending on the use case and needs of the company. However, there are some common aspects that are almost certainly desirable, which we can categorize into:
Annotation is a very repetitive task when done entirely manually. Automating parts of the process will not only reduce the average annotation time (and thus budget spent on it), but also keep annotators more engaged, as they can look at more new data in a similar timespan.
For a lot of AI related tasks, datasets can get quite large. It may not be feasible for a single person to annotate everything, and even if it were, this may not be desirable. Quality and collaboration often go hand-in-hand. Peer reviewing is a common process to detect issues and improve quality.
Additionally, the dataset may be used to try out multiple types of models. One data scientist may need semantic annotations for a segmentation task, while another may need bounding boxes to do object detection.
To overcome such challenges in the most efficient way, it’s a good idea to meet with the whole team and develop an annotation strategy together, including a review process to make sure every team member adheres to it.
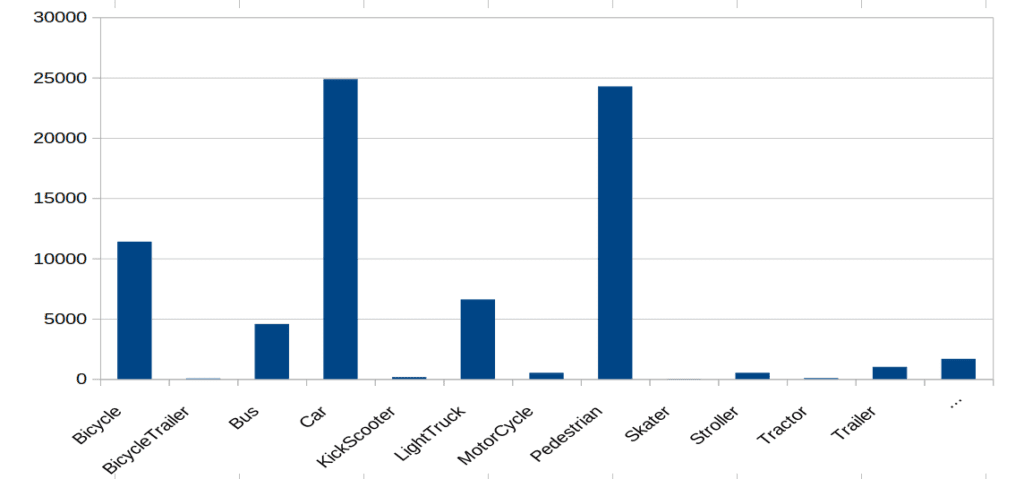
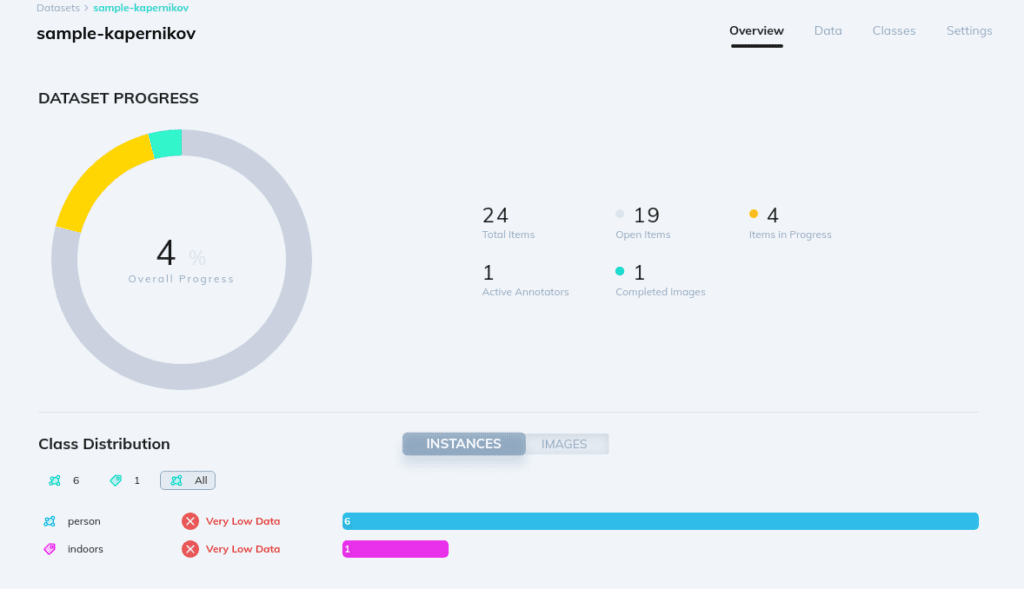
To develop high quality models, data scientists need to have a good understanding of the dataset. Statistical information like class distributions as well as filtering tools are valuable aids in this process.
Although annotation tools are getting more and more capabilities, they are most often still part of a larger toolchain that is used for a project. Being able to cope with changes in that toolchain is a big advantage. Questions such as “Can we adapt annotations to a particular format required by the AI model?” or “Does the tool offer an API to hook into my workflow?” are relevant to ask here.
Another important factor, depending on your needs, is how much control is available for deploying the tool. Can the data and services be self hosted? Depending on your company needs, you may want to host data on a particular cloud storage provider.
Annotation tools have a learning curve. If an annotation tool supports a rich set of features, it becomes more likely that you can stick to this tool for a different use case that requires different sorts of annotations, and retain productivity.
Let’s now take a closer look at some of the existing platforms. Note that all discussions hereafter are only based on a snapshot in time. If possible, we will indicate the specific version being used. We don’t really go into pricing, as that really depends on the features you need and the amount of annotation work you have.
We will discuss these platforms in detail:
Both Supervisely and v7 Darwin are paid, feature rich platforms that go beyond annotating and present themselves as an ecosystem for the entire computer vision lifecycle. Hasty is a bit more limited in its scope, but does a great job at providing AI assistants for any task you can think of. Finally, CVat is a free open-source alternative that is more limited in features but still very powerful, and under active development.
There are many alternatives that we will not discuss but do want to mention for completeness, such as:
Supervisely excels in its modularity. Its app ecosystem allows you to tailor the platform to your needs. Custom visualisation can be added directly next to the data itself using an IPython notebook, which may come in handy if there is no existing app for your needs. Furthermore, custom data transformation steps can be created using the built-in DTL (Data Transformation Language) or python scripts.
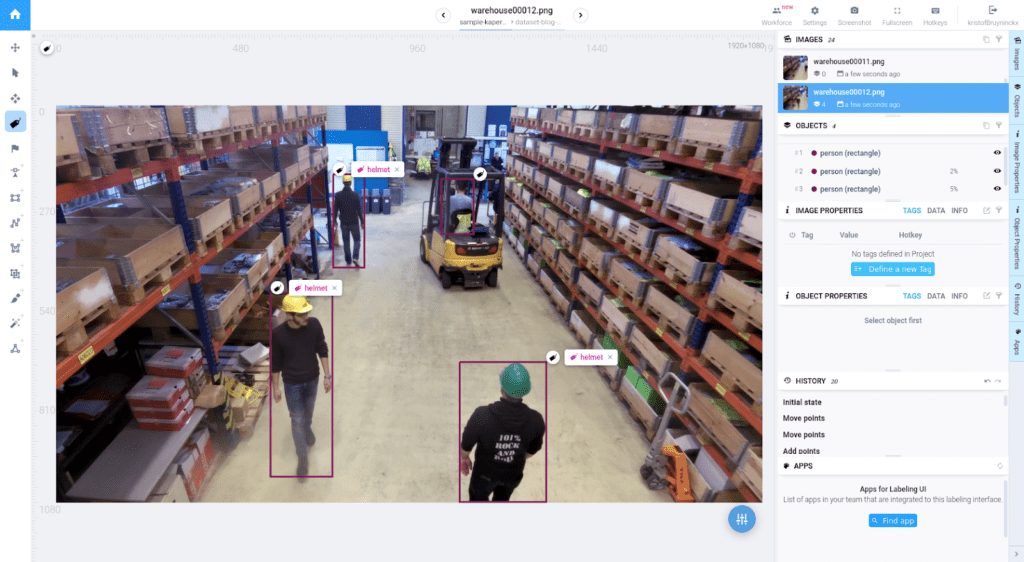
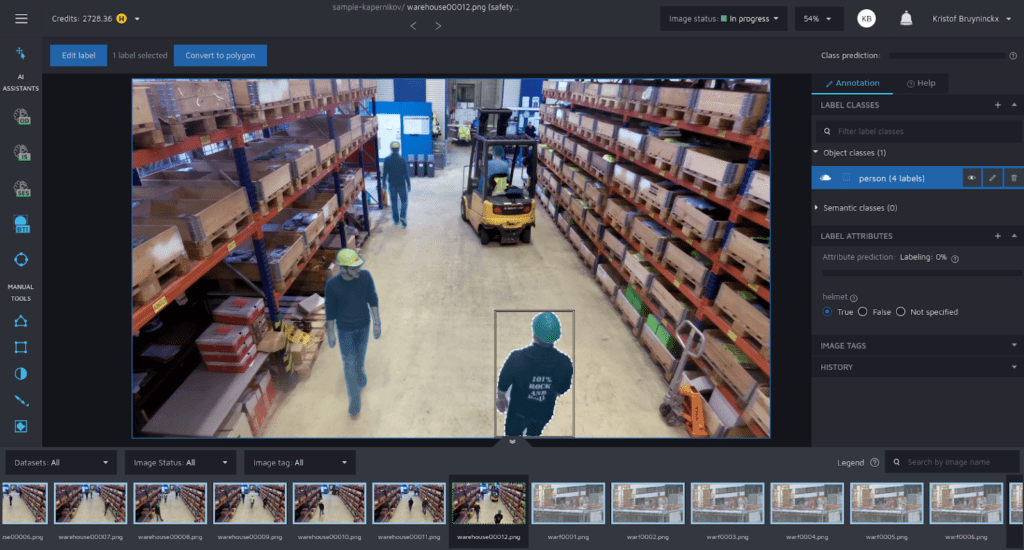
A semi-automatic annotation tool is provided that works out of the box with a generic model, and is intuitive to use. Rather than having to trace a complex object with the polygon tool or brush tool, you can simply indicate a bounding box. The tool will then work its magic to find the dominant object. If there are errors, it is easy to indicate points that should be annotated or points that shouldn’t, while the annotation updates dynamically. This can substantially increase the speed of annotation.
Fully automatic annotation can also be done, by using readily available pre-trained models or training models on your own data.
All the essential tools to divide work among a team, assign reviewers and so on are supported. One feature worth mentioning is the issue tracker. A lot of people will be familiar with this kind of functionality from version control tools such as git.
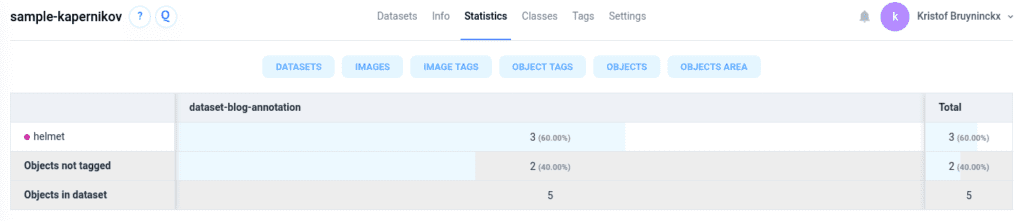
Each project offers detailed tabular statistics on annotations, image tags, object tags etc. In addition, apps can be used to generate more visual reports about various relevant distributions.
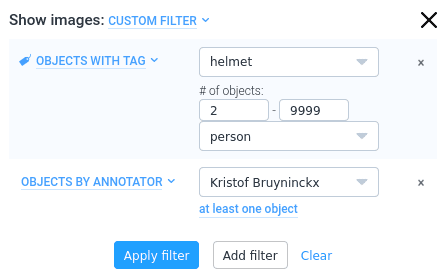
While going through data, it is easy to use filters and zoom in on specific classes, tagged objects, images that contain issues etc.
Supervisely offers a SDK (Software Development Kit) to develop your own apps within its ecosystem. This makes for an extremely flexible system. If you require some exotic feature that is not readily available, it is always an option to create your own app. On top of this, a REST api is also supported.
With Supervisely, you have the option to host agents for some tasks, but a fully self-hosted solution requires the enterprise subscription. You also have the option to store data on major cloud storage providers, i.e. Azure Blob Storage, Google Cloud and Amazon Web Services S3.
Supports polygon and brush annotations. Also directly supports polylines, cuboids and point annotations. Notably, holes can be created in a polygon annotation by subtracting other polygons.
Tags of the following types can be created:
These can be applied to both images and individual annotations.
Clean UI
Extensive image filtering
Good smart tool that can be customized using your own NN
Issue system much like GitHub issues to discuss annotations
Create and assign labeling jobs for collaborative work
Highly customizable using plugins/apps, custom python scripts and visualization notebooks. Scripts hook into the UI nicely.
Pricey
No tiled image overview
Missing COCO format support from official apps
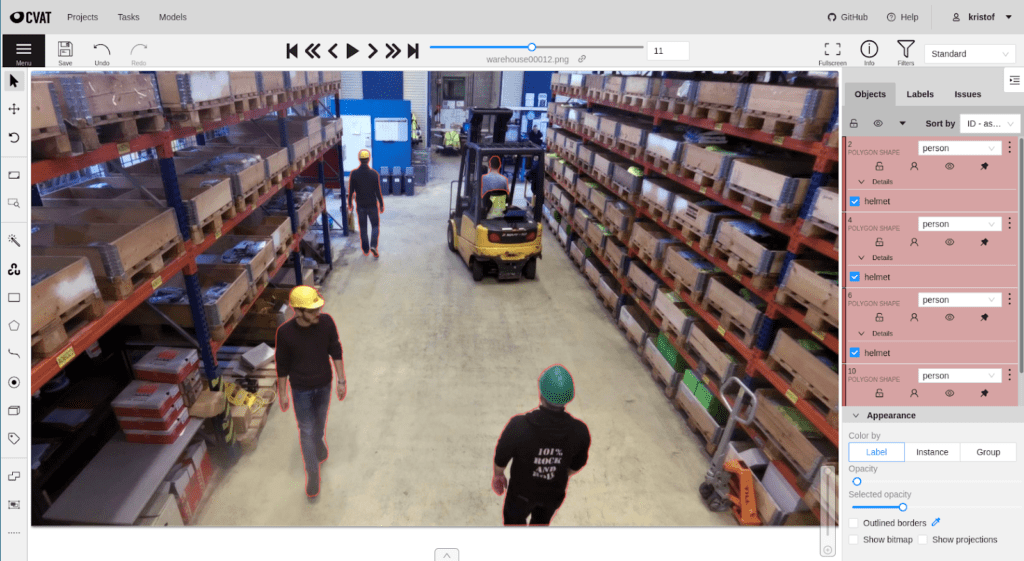
CVat is an extensive and completely free open source platform centered around 2d annotations for both images and video.
The UI is noticeably less intuitive at times. For instance, setting a filter only hides other annotations from the image being looked at. Unless you know this, there is no indication that you can also cycle through images that contain the filtered object using some key bindings. There is no visual feedback – such as a list of thumbnails – about the filter.
One thing that is also lacking is project management. A project can be created and each data upload results in a new task. Afterwards annotations for each task can be exported, but not for the whole project.
For semi-automatic annotation, a tool called DEXTR is provided. It works by selecting some extreme points of an object, after which the complete segmentation is derived.
Another interesting tool comes from integration with OpenCV, an open source project around computer vision. From within CVat, you can access its intelligent scissors tool, which allows you to trace an object outline rapidly with visual feedback.
Fully automatic annotation annotates all objects in an image, but you will likely have to make corrections here and there. The downside is that this takes a bit more time to set up.
CVat provides the possibility to divide work and set up a review system. Discussions can be started as well in the form of comments directly on images.
There are powerful options to set and combine filters, but visually it is a bit less intuitive compared to the other platforms. This is mostly due to the lack of a thumbnail overview that matches the filter settings.
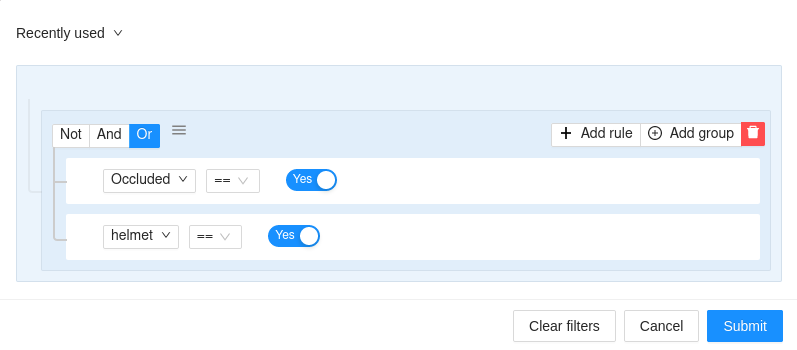
Statistics are minimal and only available for jobs assigned to annotators (rather than project wide).
CVat offers docker images to easily deploy the server and client side. The user has full control over the whole toolkit, and is as such free to decide how and where to deploy the service and store the data.
There is no plugin system to extend functionality, but it does offer a REST API to interact with the outside world. Dataset maintenance is limited, but a separate tool, called datumaro, is supposed to be used for that. Lots of out of the box import/export formats are supported as well.
Cvat supports polygon annotations but notably lacks a brush tool. Often, especially with a mouse, a polygon tool works just as well if not better, but a brush can be convenient to make corrections, and it is a tool that lots of people are familiar with. Cvat also lacks functionality to annotate polygons with holes. A workaround is available for this, so that exported masks can contain holes (see the user guide), but it is not ideal. Besides polygons, cuboids, polylines and points are also supported.
Tags are supported for both annotations and entire images. The following types are supported:
Free and open source
Lots of out-of-the-box export formats
Only supports Chrome (officially)
UI not always intuitive
No thumbnails, no statistics overview for the entire project (only for tasks)
Project management is lacking
No support for holes in polygons
No brush tool

v7 Darwin is a real pleasure to use. Of course this is somewhat subjective, but we feel it has a very clean UI and its built-in tutorial is an excellent way to get familiarized with its features. The tool consists of 3 major elements: dataset management, annotation and an AI module to train and manage your models. Also included is built-in data version control. This is one of those features that really shows the platform is about much more than just annotating.
The AI based automation tools offered by v7 Darwin are similar to those of Supervisely.
One thing that stands out is the ability to discard images for a variety of reasons, such as blurriness. These get submitted for review in the same way as annotations, and are just another tool to maintain a qualitative dataset.
A comment feature is also provided, similar to that of CVat.
Filters can be set and combined, but filtering on object tags is not possible. The same filters can also be applied in the annotation screen.
There are also some basic statistics tools available to gain more insights.
A SDK and REST API are provided, although these are not as much on the forefront as with Supervisely. Webhooks are also available, which can be useful to publish notifications in a Slack channel, for example.
A wide range of formats is available to import and export data.
In the higher tier subscription services, data can be hosted on your own AWS S3 cloud.
When it comes to the annotation toolbox, v7 Darwin offers mostly the same features as Supervisely. They do offer an ellipse tool as well. One thing that stands out is its sub-annotation feature. The best example of this are directional vectors. Each annotation can be supplemented with a direction.
Tags are restricted to be a blob of text. Rather than having a color tag, with values red, green and blue, there would be tags for each color directly. Especially for numerical tags, this can be limiting, with each distinct value needing its own tag.
With v7 Darwin, your uploaded datasets can still retain a folder structure, and folders can be activated or hidden based on your view settings. While tags are recommended because they can be combined, sometimes it can still be useful to retain some legacy folder structure, or to have some very basic subdivision for things like batches recorded at different times.
Powerful sub-annotations alongside a tag system, for example adding directional vectors.
Folder structure can be maintained and enabled as a view.
Data version control is also supported.
Tags are just a blob of text. For numerical tags, this can be limiting, as each distinct value will need its own tag.
While both Supervisely and v7 Darwin are purely subscription based services, Hasty has a different business model. It is a mixture of subscription and pay-for-what-you-use. Both storage and usage of AI features are charged for by paying credits. Credits are obtained through a customized subscription that also gives access to extended features.
For semi-automatic annotation, the same DEXTR tool as we saw for CVat is offered.
Additionally, there is a tool to convert bounding boxes to segmentations.
There are some additional non-AI tools, such as a color based magic wand and a contrast contour selection tool.
For fully automated tools, an approach of user convenience is taken, as no setup is required at all to use AI assistant features. Once enough samples are manually labeled, these assistants become available automatically, trained on previous annotations. All of the tools are available directly from the annotation view and provide feedback on what to do to start using them. This makes for a very intuitive user experience. The tool even includes AI assistants to automate object and image tagging.
Images can be marked as requiring a review, but issues or comments cannot be added to specific areas of an image.
Work can also not be divided within the tool, for example splitting a large set into several jobs, and assigning different users and reviewers.
Yet another AI tool can help you with quality assurance, to track down mistakes such as mislabeled or incomplete annotations, missed objects or artifacts in the dataset.
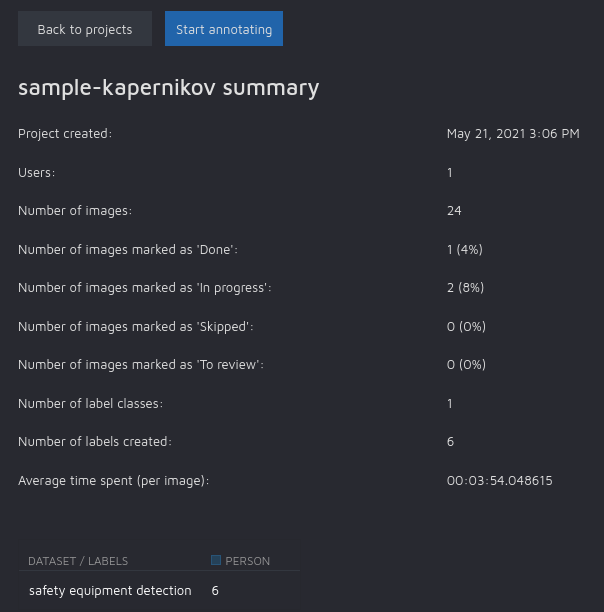
Some basic project statistics are provided in a tabular form.
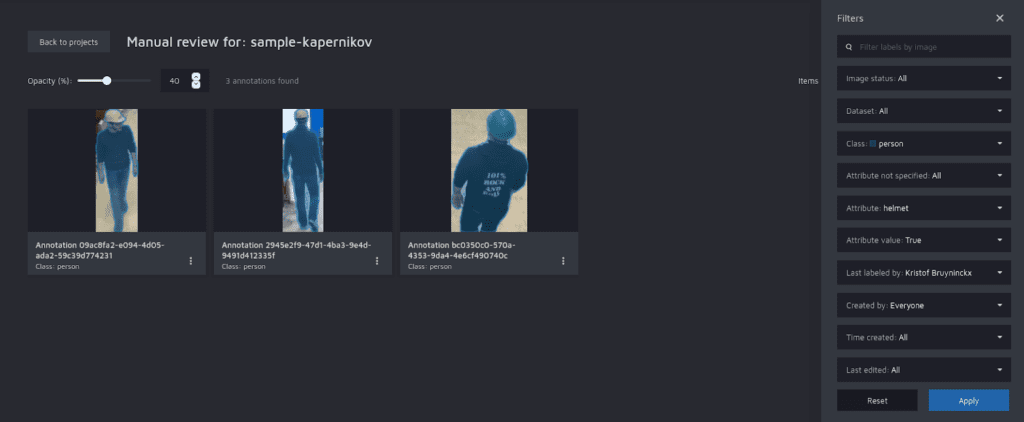
To filter, a separate review module is provided. The tiled view gives a nice overview of all annotations that match the filter settings. It is possible to filter on object tags, but multiple tags cannot be combined.
Hasty offers third-party cloud storage for Azure blob storage, Google cloud and Amazon S3. A fully self hosted solution can be requested, but will charge much higher fees. An API is offered for integration into an existing pipeline, but there is no such thing as a plugin system. More control over the AI assistant models is only possible in the premier plan, for which you have to contact the sales team.
Export format options are limited: a custom Hasty format, pngs supplemented with json and COCO are supported.
Supports both polygon and brush annotations. Polygon tools cannot be used to create annotations with holes. With a mask, it is possible to erase internal parts using a brush, but if the annotation is converted to a polygon, the holes are lost.
Annotation tags are supported with the following possible types:
Image tags are available only in a boolean form.
Intuitive and extensive AI assistants
Good UI and tooltips, easy keyboard shortcuts
No polygons with holes (only indirectly when exporting masks)
Few export formats
In this blog post, the discussion is restricted to working with 2D image data. This really only scratches the surface of annotating. There are a lot of exciting computer vision applications that work with different types of data, notably video and point clouds. These come with their own challenges, such as interpolation between frames of a video.
Even within the world of 2D images, there is a huge variety of tasks that translate to different kinds of annotation work. Aside from pixel segmentation and bounding box predictions, there is also OCR (optical character recognition) and pose estimation. These tasks come with their own set of annotation tools, which can be coupled back to our guidelines. You could, for example, have a look at keypoint templates, and come to the conclusion that it is a way of automating annotation work for pose estimation.
The key takeaway here is that these guidelines, alongside company needs, should make it possible to make an informed decision, even as these tools and needs undoubtedly evolve over time.