CopernNet : Point Cloud Segmentation using ActiveSampling Transformers
In the dynamic field of railway maintenance, accurate data is critical. From ensuring the health of ...


Published on: February 22, 2018
In a spirit of continuous improvement and knowledge sharing, Kapernikov recently organized another successful mini-hackathon event. This time, the Kapernikov team and a few colleagues from other companies came together in Aalst for the purpose of building upon recent work that was done for Infrabel.

In order to improve vegetation management alongside its rail tracks, Belgian railway infrastructure manager Infrabel asked Kapernikov to help with the automatic detection of vegetation in point cloud data generated by mobile LiDAR scanner systems. For this project, Kapernikov had successfully applied a point-based classification based on local geometry. That methodology was also used as a starting point for the mini-hackathon. However, the purpose of the mini-hackathon was not only to improve this initial methodology but, more importantly, to try various new approaches to the problem by using different combinations of state-of-the-art methods.
Kapernikov welcomed participants from diverse backgrounds and with various skill sets. Each participant was allowed to select a task from a list of to do’s that corresponded with his or her profile and skill set, and then they were encouraged to go through the suggested literature and try their own implementations. They only received a few initial guidelines and some code for each task, so everyone was able to explore and develop their own ideas.
During the event, the participants used point cloud data sets provided by Infrabel. The tasks ranged from developing tools for simple point cloud processing to more advanced point-cloud-based object detection and semantic segmentation. However, the team’s central focus revolved around three specific tasks:
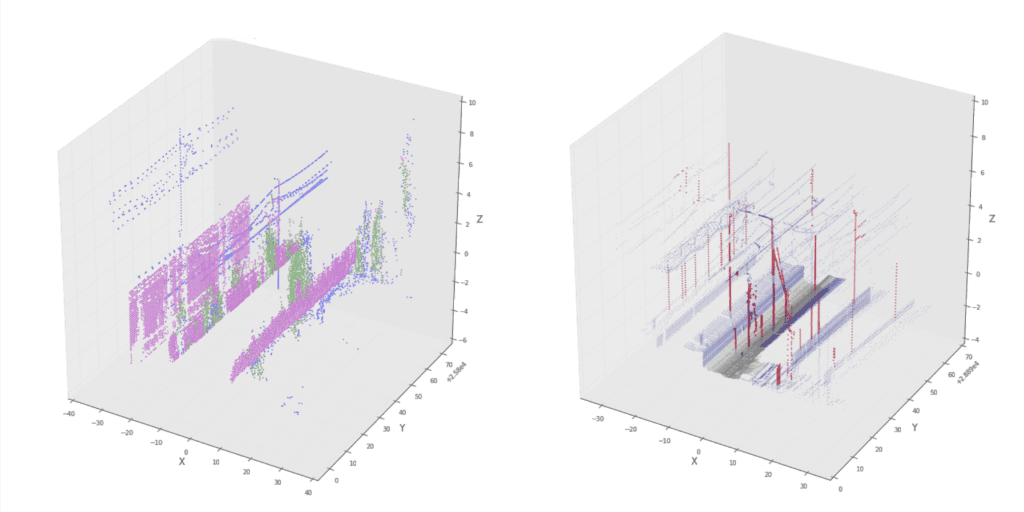
After a full day of coding, we managed to reinforce our methodology with a pole detection method that identifies poles as upright linear structures with no other points in their vicinity. Regarding the supervised classification, the results have not significantly improved, but we believe that the SVM classifier might perform better with different sets of features. Finally, even though the ground detection methods we tried seemed promising, we still need to look further into the relevant literature in order to identify which methodology is more appropriate for our data.