RINF 2026: What Railway Infrastructure Managers Need to Know
Visit our dedicated RINF roadmap site: roadmap2rinf.eu The European railway infrastructu ...
Published on: April 27, 2026

Agentic AI can dramatically improve how knowledge workers operate, but only when it is applied with discipline. We asked Frank Dekervel, partner and CTO at Kapernikov, what has actually changed, what breaks, and what a CTO should do on Monday morning.
In one sentence — what does agentic AI change about how knowledge workers in asset-intensive industries do their work?
Frank: In our business of software development, agentic AI turned the knowledge worker from an executor into a process engineer — of the process they used to execute themselves. Less time writing, more time on problem definition, review, and steering the process when it goes wrong.
I think it will translate — with some delay — to knowledge work in general.
Counter-intuitively, this will raise, not lower, the bar for knowledge workers. Some tasks get easier, but the possibilities go way up: suddenly it becomes feasible to do an analysis quantitatively, supported by data instead of just gut feeling. Knowledge workers will spend more time thinking, steering and reviewing, just like we do now, and less time will be spent just executing a plan.
Why now, and not two years ago during the ChatGPT hype?
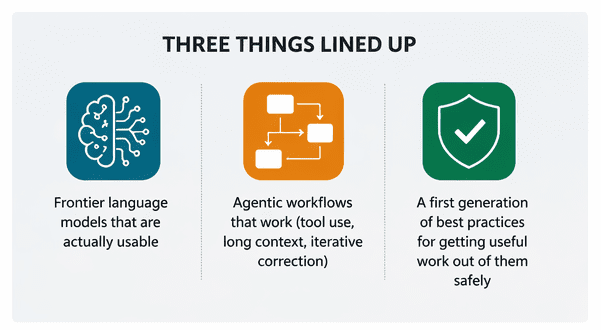
Frank: As for software development, three curves converged: mature frontier language models, mature agentic workflows (tool use, long context, iterative execution with error correction), and emerging best practices for safe and high-quality use. We’ve been working on this for longer than a year, but the tipping point — where it makes no sense to deploy a knowledge worker without the help of an agent — is a few months behind us.
For knowledge workers in general, I think we are lagging behind a bit: general-purpose agents exist but are less mature, and lots of software used by knowledge workers is not yet agent-friendly.
Asset-intensive industries are a particularly interesting case. Physical assets live longer than IT systems, so information about them is by definition heterogeneous — spread across generations of systems and formats. That heterogeneity was historically the killer of data integration projects: infeasible on cost or time. Agentic AI can shift the feasibility line, moving projects from “infeasible” to “challenging,” and from “challenging” to “easy.”
You’ve been using agentic coding internally since 2024. What has actually changed — in output, in who does what, in how you scope and price projects?
Frank: We spent quite some time figuring out how to reap the benefits of agentic coding while, at the same time, ensuring the software we make remains high-quality, scalable and easy to modify in the future.
This has been non-trivial. AI agents can now very quickly build a first version, but when not managed, the speedy initial delivery is followed by a much slower bugfixing and stabilising phase. We are now able to keep on iterating quickly, while being in control of quality, technical depth, security and scalability at the same time.
For this, we did several things:
An important point: these investments are not there to optimise speed of initial delivery (which is already great), but the total cost of ownership of software throughout its lifetime. A common pitfall in the agentic era is to judge success by the speed of initial delivery, which is only a fraction of the total project cost. Defect rate, scalability, and how easy it is to evolve and change software are much more important in the long run.
So manual programming is disappearing at Kapernikov?
Frank: Almost. Many of our people could still do it — and that’s critical. Because even the best language models make one or two concretely harmful errors per human per day. Small in relative terms, but the human safety net is absolutely necessary. And the competencies that make someone a good safety net are harder to name or assess than “knows Python”: critical thinking, software architecture, appetite for simplicity.

We’ve rewritten our competency matrix. The role of the junior is explicit in it: today’s juniors are tomorrow’s seniors. The question isn’t whether they’re redundant, but how they deploy AI agents to grow faster. We invest more in coaching and mentoring than before, not less.
An early study — METR, mid-2025 — found that developers using AI agents actually overestimated their own productivity. Real speed didn’t match perceived speed. How do you guard against that?
Frank: Working with an AI agent often makes people overly optimistic about what can be achieved, and this optimism comes from the speed at which the initial implementation of a project is finished. The challenge is to maintain a high speed once past the initial implementation, and this is where the investment in an agent harness, architecture and methodology pays off. A high defect rate or a substantial rewrite to make software production-worthy can completely kill the advantage of the head start given by agents.

Coding is one profession. For a geologist at an offshore operator, an asset engineer at a rail manager, a data steward at a utility — what can agentic tools do for them today, and what is still blocked?
Frank: Agentic tools originally built for code are increasingly applied to knowledge work. Decisions that used to be made on feel are now evidence-based — even by knowledge workers who never wrote code. An asset engineer at an infrastructure manager can today ask an agent to correlate failure reports on a given component type with maintenance history and live sensor data, and prepare a prioritisation proposal. What used to require a data scientist and several days now takes hours — and sits closer to the engineer, without translation layers.
What’s the dominant bottleneck to wider rollout?
Frank: A contrarian answer: the most-cited bottleneck is “data quality,” but for knowledge work in asset-intensive sectors, the real bottleneck today is security or governance. The challenge is to guarantee good security without killing the speed advantage agents offer.
We see CISOs at all our major customers pushing back on the use of general-purpose agentic tools, and rightly so: the tools frontier-model vendors provide for running an agent in a secure way are simply not adequate as of spring 2026 (if they exist at all), which makes securing an agentic workflow a case-by-case exercise, for which no general solution exists.
This makes a company-wide roll-out very hard.
Agents are powerful, but there are serious incidents reported — prompt injection, data exfiltration, supply chain issues. How do you build systems where a knowledge worker can be productive without unacceptable exposure?
Frank: The question is not whether agents can operate on company data — they can. The question is how. The broad autonomous agent with unlimited access to data, communication, and software installation — what the market often demos today — simply doesn’t work in production yet. We’ve experimented with it. What it can do is impressive. What it actually holds up to in production is not. We hear from peers that several companies have shelved such setups after a few weeks. Security was the main — but far from the only — concern.
The architecture that does work today: the embedded agent. Software gets — alongside a GUI and an API — a natural-language interface. The agent lives inside the software, not around it. All frontier models now support tool-calling (deciding if an external tool is necessary and using it if so); embedded agents have become mature because of it. The agent operates in a tightly controlled environment: the software defines what it can see and do. You keep control of all data flows, you bake in security, and you add context-specific guardrails that are far better suited than what generic agents offer.
A concrete example?
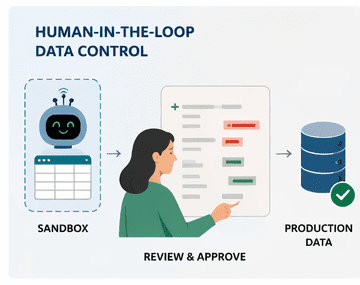
Frank: We’re building an embedded agent for an asset-inventory system. The agent modifies data freely in a sandbox — it experiments, proposes, validates. Changes are not published without explicit human consent, and the agent has no way to bypass the consent step. That’s architecturally enforced, not left to the agent to respect. It’s the operationalisation of the “human safety net” principle applied to data operations.
An under-appreciated point: for good code generation you need frontier models today. For embedded agents you don’t. The environment is so much more controlled that much smaller models suffice. On-prem deployment without exuberant hardware becomes realistic — data doesn’t leave the company, cost per query drops by orders of magnitude, and vendor lock-in on frontier providers disappears.
The line we draw: reading, proposing, analysing, checking against a pre-written checklist — autonomous. Every write operation on company data, every external communication, every irreversible action — human-in-the-loop. On an agent operating on personal data, 95% reliability is liveable. On company data, 95% is catastrophically insufficient. The difference isn’t harder, it’s an order of magnitude different.
Shadow AI — employees feeding company data into personal ChatGPT accounts — is reality in almost every company. What frameworks should companies apply?
Frank: Governance is not about forbidding (it is almost impossible and probably undesirable to prevent the use of general-purpose agents). It’s about controlling the actual risks. The risks aren’t new. What is new: the barrier has collapsed so far that people without the background to quantify risk are now working with AI tools.
For chatbots, a solution can be to provide a company-sanctioned official chatbot to use. Agents (like Claude Code, Antigravity, and CoWork) present much bigger risks, because they operate with access to company infrastructure and data.
The most important governance task in 2026 is awareness: people must genuinely understand the risks associated with AI in order to cope with them. E-learnings won’t be enough. Time will have to be spent: training, discussion, coaching, periodic meetings between business, IT and security — around concrete use cases.
You’re CTO or CDO of an asset-intensive company — rail, water, energy, offshore. One thing you start this month, one thing you stop.
Frank:
The choice between keeping agentic AI out (safe-feeling, actually irresponsible) and ungoverned adoption (irresponsible) is false. The third path is structured learning — benefits, risks, CISO implications together. Whoever doesn’t start that learning process isn’t building certainty. They’re building backlog.
Want to talk about how agentic AI fits your infrastructure data landscape? Get in touch.