Interview with Frank Dekervel: Agentic AI, Applied
"Agentic AI turns the knowledge worker fro ...
Published on: March 9, 2022
At Kapernikov, we like to apply deep learning, especially for challenging computer vision projects. We recently did this for Telraam, a project that aims to monitor different categories of traffic users in the city. This task was particularly challenging, because we had to work with a limited hardware budget (less than €20) and ensure the privacy of people that are monitored on the street.
In view of these constraints, we selected a sensor that performs embedded counting, and only communicates the telemetry data to the cloud. This way, we don’t need to upload the entire video stream, which allows us to save bandwidth and guarantee system privacy by design. The sensor is a Kendryte K210, a low-cost micro-controller that includes a camera interface, a neural network accelerator (kpu) and a dual core cpu.
Working with a device with limited power is a performance bottleneck. Unlike classic applications where we can always add more GPUs, here we needed to rely on the capabilities of the available hardware. Based on Kapernikov’s long experience with optimizing industrial computer vision applications, for throughput and latency, we were able to find an appropriate solution for Telraam.

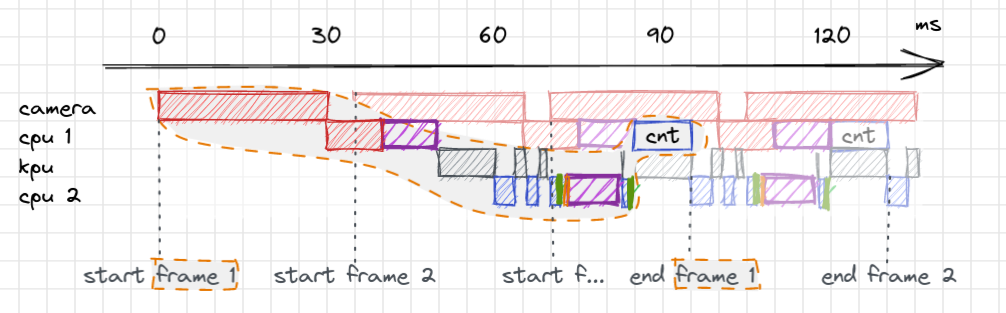
A sensor is capturing images of the street. In each image frame, a convolutional neural network (called YOLO) detects the objects in that frame. Next, we associate our detections with known objects that we have detected before. This is called ‘object tracking’. Finally, we decide whether or not we count the object (no need to count a parked motorcycle). The results are uploaded to the cloud.

Running our neural network for object detection – a variant of yolo3 – initially took 134 milliseconds per frame. Because of the large time span, the tracking performed poorly on fast moving objects. Instead of spending months of research on how to improve the tracking algorithm, we wondered whether we could increase our frame rate.
A quick profiling session of the first version of the code resulted in something that looks like this:
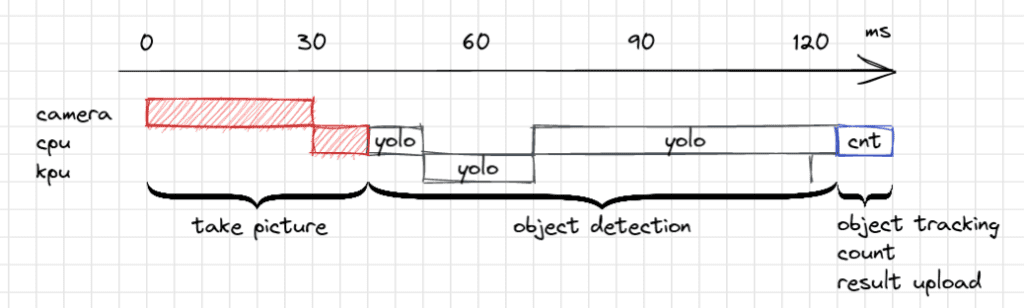
As the “take picture” phase is showing, the process starts by waiting for the camera to finish taking its picture, followed by a bit of image processing performed on the CPU. After this, the YOLO inference is done in part by the KPU, although the CPU also needs to do some (non-accelerated) parts. This code is fully sequential: the cpu, camera and kpu all spend a significant amount of time waiting and doing nothing. There must be a more efficient, concurrent way to do this.
The first and easiest way to improve the frame rate is to eliminate the waiting time. Instead, we work with the previous frame while the camera is still doing its job. This way, cpu and camera tasks can overlap. Of course, this requires extra (already scarce) memory: we need a buffer of 147Ko to store the last image while the new one is coming in. However, we already win 41 milliseconds.
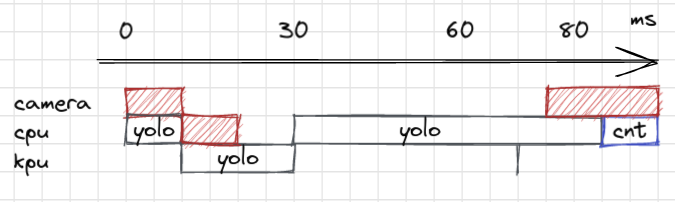
The astute reader will notice that there is a gap between the YOLO block and the “picture” block. This is for illustration purposes. In reality, the camera and the “picture” block could happen anytime, since they are asynchronous (the order could be different in reality). YOLO will simply pick up the latest picture taken.
Now that we have the camera out of the way, let’s have a look at our other resources. Apparently, we are almost using 90% of the cpu. Conveniently, that is without considering the second core that is at our disposal. If we move the task of running the YOLO model to the second core, it costs us another 147 ko of buffering, but this time, we only make up with 10 milliseconds.
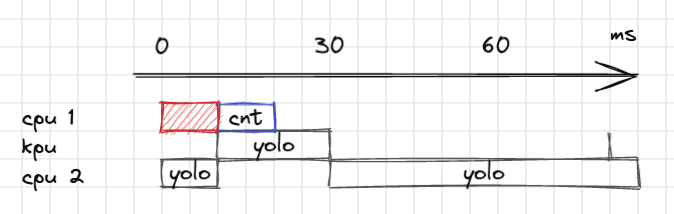
Before we continue, it seems almost unfair to have such a huge workload imbalance between the two cores. The first block is a trivial upload of the picture to a kpu dedicated memory. The only problem with putting it back in the first cpu is that “Uploading is prohibited when the kpu is busy”. Apparently, we are at the mercy of the chip’s specification. But there is a hidden way: direct memory access. This is a feature which provides access to the main system memory, independently of the cpu.
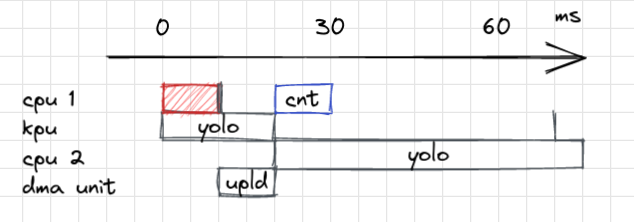
Although this hack does not conform with the unit’s specifications, it has no apparent drawbacks. It does not consume memory, and it enables us to reach the glorious 13.33 fps mark.
At this point, you may expect that the next step is to make the work done by the kpu and by cpu 2 overlap. But did you notice that gray line at the 70th millisecond ? That is right, there is a late kpu job at the end of YOLO. What’s more, the actual workflow looks a bit different, as the neutral network accelerator is constantly interrupted by the download of the outputs.
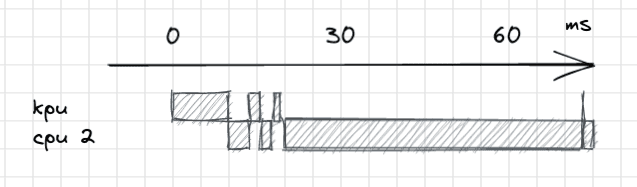
A finer benchmark reveals some interesting facts:
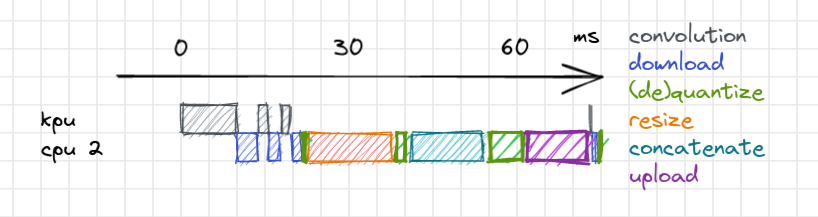
The first thing we can do is add a specialized path for upscaling by a factor of 2. The standard implementation provides a generic method that performs a (bilinear) interpolation, but this involves costly floating point operations. Without much effort, this path reduces the resizing to 1 millisecond.
Next, we can remove the channel concatenation operations. In the memory, the data is arranged channel by channel. This means that, provided that the previous operations store their outputs at the right address, there is nothing to do for a concatenation.
Finally, we can look at the operations that convert float values to an 8 bit float (quantize) and vice versa (dequantize). Those operations apply a trivial linear mapping, with some coefficient. In our model, there is an occurrence where the two mappings cancel each other. We can thus remove both operations.
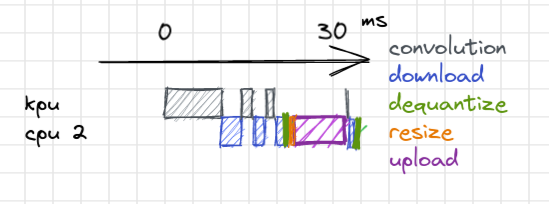
A nice side effect of getting rid of all of those redundant operations, is that it reduces the memory footprint to run the model by 1.1Mo.
Thanks to a bit of concurrency and various model optimizations, we almost quadrupled the frame rate and reduced the overall memory footprint by 850 ko (this represents 14% of the RAM capacity).
In summary, even a $10-$15 chip can run a modern deep neural network in real time, and as a result tackle the tracking problem. Besides reaching a very high frame rate, this kind of optimization allows us to use a bigger model network if we have to. It’s not exactly plug and play, but diving into the system details does pay off.