Interview with Zowi: AI for Marine Survey Data at GEOxyz
"We help GEOxyz survey the seabed efficien ...
Published on: March 25, 2022
Hardware is continuously evolving and new types of training frameworks, AI models and runtime environments are popping up every so often. How do you deal with this constant change? And how can you make sure your machine learning investment is protected for the future?
Developing a machine learning model is a considerable investment of time, money and resources. It’s an effort that needs to pay off, and you want to be able to deploy your model into a production environment for a long time. But in order to do that, your model needs to be able to cope with constant hardware and software changes. All the while, you expect high performance of your machine learning model in a constantly changing ecosystem.
This reality begs the following obvious questions:
This is not to say that change is a bad thing. Obviously, technology is getting better, more powerful and more efficient every year. So, why would you not want to take advantage of that?
But to deal with change efficiently in the long term, you need to be able to switch smoothly from one environment to another. By this, we mean that you may want to change from one training framework or runtime environment to another, but also that you may want to train and generate your model in one particular framework and then deploy your model in another runtime or inference environment. Flexibility and portability are key.
Is there a way to be more flexible? There is. The Open Neural Network Exchange (ONNX) standard has been developed to make this possible. ONNX is a uniform format that acts as an intermediate between two environments, so you can easily go from one environment to the other. Thanks to ONNX, you can easily build and train your model in one particular framework, and deploy it in another one. This makes ONNX a powerful open standard that prevents you from being locked into any framework and that ensures your model will remain usable in the long run.
Thanks to the ONNX format, you can:
In practice, an ONNX workflow may look something like this:
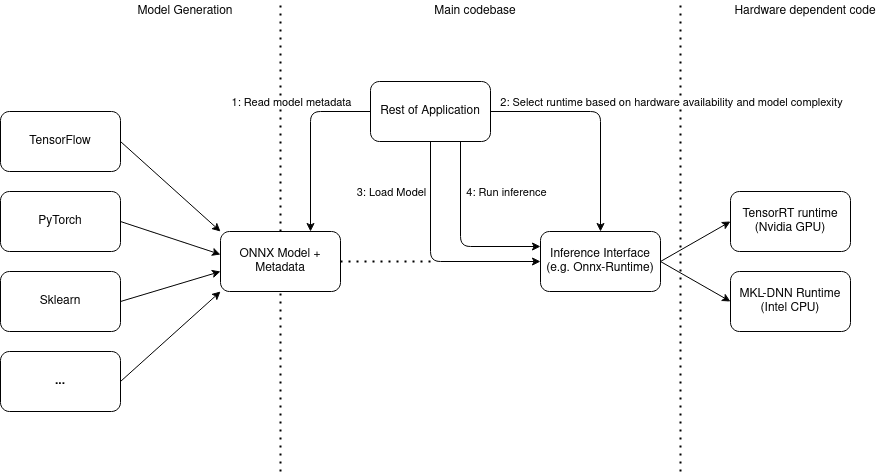
At Kapernikov, we like to work with ONNX in our machine learning projects, because it gives us more flexibility in our software and hardware selection. Thanks to ONNX, we can use the frameworks and platforms that best fit the customer’s needs.
For example, we may want to train a model in the TensorFlow framework. Using ONNX, we are not necessarily tied to the deployment methods offered by TensorFlow. In fact, after conversion into ONNX, we can load the converted model into any runtime environment, without having to make severe code changes.
Also, inference frameworks are often tied to specific hardware. For example, TensorRT is linked with NVIDIA GPUs. But whenever we decide to use another, less complex model that can also perform real-time tasks on the CPU, things become a bit complex. While inference frameworks mostly support the ONNX format, they all offer their own API. This means spending budget on supporting new environments when needed . We solve this by using ONNX Runtime, another form of standardization over the different inference frameworks, closely tied to the ONNX standard. ONNX Runtime allows us to run our model as fast as possible on the hardware of our choice, with minimal changes to support said hardware.
The ONNX format not only successfully tackles the issue of evolving technology over time. It also allows you to exchange models between different teams more easily, to adapt your deployment hardware due to changing requirements, or to swap your machine learning framework for another one because the task has changed.
Technology will continue to change. If you want to take advantage of those hardware and software evolutions, but you don’t want to redevelop your model or make huge code changes every time, then the ONNX format is a good way to protect your investment.
Do you have questions about the use of ONNX or ONNX runtime? Let us know, we can help.