Interview with Frank Dekervel: Agentic AI, Applied
"Agentic AI turns the knowledge worker fro ...
Published on: October 30, 2018
Remember the time when you scheduled several different batch jobs to query, transform and aggregate data from different sources? Remember that one job always kept failing, always a different one compared to your previous attempt? And worse, you had to keep track of everything or even relaunch your pipeline all over again?
The developers at Spotify surely remember. That’s why they developed a solution that they now use for tens of thousands of tasks. That solution has the same name as the second best known plumber in history: luigi.

Luigi is an open source framework that has been designed to help you build, monitor and troubleshoot your data transformation pipeline. From running SQL queries, dumping results into a database, storing intermediate results and more, luigi can manage thousands of jobs spanning several weeks. It has been developed by Spotify, open-sourced in 2012, and expanded by hundreds of developers. It is currently used by dozens, if not hundreds of companies around the world to process and transform data.
In this article, we present how luigi works and how you can set up a simple reporting pipeline based on an SQL database and query files.
Luigi is mainly based on two object types: Tasks and Targets. The idea behind luigi is that usually, a process produces an output, which is stored in a file or database before being picked up by another process to perform transformations and/or aggregations. Therefore, if the output produced by the first process does not exist, the second process cannot be run. For luigi, a process is called a Task and the output a Target. The premise is simple: a Task produces a Target, and the existence of this Target will be used by dependent Tasks to assess whether or not they can be run.
This allows users to easily build entire schedules of Tasks that depend on each other. Luigi will first verify if the topmost Task’s Target exists. If not, luigi will verify whether the dependencies are complete (whether their Targets exist) and run them if they don’t. If these dependencies have dependencies themselves, luigi will verify them as well, and so on until it finds Tasks that are complete or that do not require dependencies. It will then run the whole tree of dependencies to finish by the topmost Task.
Tasks offer three different methods to override:
In addition, there are special kinds of Tasks that do not require all three methods to be set. For example, ExternalTask does not require a run() method and represent an external resource, i.e. a Scala Spark job. WrapperTask has no run() nor output() method and is used to aggregate multiple Tasks that have to be run together.
Targets offer one method: exist() method, which should be overridden and should return True if the Target exists. Luigi already provides a few of them, i.e. LocalTarget, which represents a file on the system. Many more can be found in the different contribution packages, depending on your preferred technology stack.
In addition, Luigi provides a way to pass on parameters to the Tasks to be run, under the form of Parameter objects. These can represent any type of object that can be passed on to a Task, and that will be used to perform the Task and verify dependencies. Parameter objects are defined at class level, but their value is assigned at instance level. Luigi will regard two Task instances with different Parameter values as different. The different Task instances will be run separately, unless one of these Parameters is set to be insignificant.
Now that we have presented the main principles, we will introduce a way to put a pipeline in place that will output an arbitrary number of reports based on SQL query files.
Let’s say you have a series of databases and that you need to produce Excel reports based on SQL queries ran against these databases. You want to automate that process, so that whenever you put a new SQL file in a dedicated folder (one per database), a report will be produced and dropped in an output folder, with the same name as the query file.
For the sake of this exercise, we will use a csv file generated by means of the USGS earthquakes API, on a period between 15 September 2018 and 1 October 2018, worldwide, with all magnitudes. You can access the data on Github or download it here.
The generated csv will be located in a folder called ‘data’ in the same directory as the code. It will then be picked up by a Luigi Task and sent to an SQLite database located in that directory. This will be done via a pandas DataFrame, to focus on the luigi code. We will use SQLAlchemy to manage the connections to the databases because this offers the right level of abstraction here.
The idea is to have two directories: ‘queries’ and ‘results’. The ‘queries’ directory is subdivided into different directories, each one hosting queries related to a different database. Each valid query added in one of the subdirectories will be run and will produce a report, such as an Excel file.
First, we have to define a number of variables that will help to create modular code that can be reused or modified later. First, we import the required modules.
///code: le_utils.py
# This file will be imported from all the other files
# Basic imports
import sqlalchemy as sa
import os
# Main DB against which the queries will be run
MAIN_DB_PATH = 'eq_db.db'
# Mapping of string: sqlalchemy engines to manage connections to different
# databases via the use of luigi Parameters
DB_ENGINES = {
'eq': sa.create_engine('sqlite:///{}'.format(MAIN_DB_PATH))
}
# Useful folder paths
OUTPUT_FOLDER = os.path.join('results')
QUERIES_FOLDER = os.path.join('queries')
Since we use SQLite, we have to create our own Target object to ensure that the data we have sent to the database has been sent correctly:
///code: le_targets.py
import luigi
from sqlalchemy import engine
class SQLiteTableTarget(luigi.Target):
'''Target to verify if a SQLite table exists, independant of last update'''
def __init__(self, table: str, eng: engine.Engine):
super().__init__()
self._table = table
self._eng = eng
# The exists method will be checked by luigi to ensure the Tasks that
# output this target has been completed correctly
def exists(self):
query = '''SELECT name FROM sqlite_master WHERE type='table' AND name='{table_name}' '''
query_set = self._eng.execute(query.format(table_name=self._table))
return query_set.fetchone() is not None
If the SQLite database does not exist yet, we need to create it and put our data in it. In the case of SQLite, we can use a luigi Task to do it, with a Parameter equal to the name of the database we want to create:
///code: le_create_db.py
import sqlite3
import luigi
class CreateDB(luigi.Task):
db_file_name=luigi.Parameter()
def requires(self):
pass
def output(self):
return luigi.LocalTarget(self.db_file_name)
def run(self):
with sqlite3.connect(self.db_file_name) as c:
pass
When working with SQLite, creating a database is as easy as connecting to it by means of a path and filename. Since these are Parameters, they can be reused if needed. In order to verify that the connection has created the file, a LocalTarget with the name of the database is used. The requires() method returns nothing, meaning that this Task has no dependencies.
Furthermore, luigi ensures that Parameter values can be used as any other property of the Task object, via simple attribute look-up.
Once our SQLite database has been created, we need to put data in it, again by means of a luigi Task. This Task has a dependency, the one we created earlier, specified in the requires() method. This Task outputs an SQLiteTableTarget that was defined earlier.
The engine_name is passed on as a Parameter and is used as a key to get the SQLAlchemy database engine defined in le_utils.py
///code: le_fetch_data.py
import pandas as pd
import luigi
from le_utils import *
from le_targets import *
from le_create_db import CreateDB
class GetEQData(luigi.Task):
'''Task to get the earthquakes data from USGS website and send them to the specified database'''
# Defaulting to the eq engine, linked to the eq_db sqlite database
engine_name = luigi.Parameter(default='eq')
def requires(self):
return CreateDB(db_file_name=MAIN_DB_PATH)
def output(self):
return SQLiteTableTarget(table='earthquakes', eng=DB_ENGINES[self.engine_name])
def run(self):
data = pd.read_csv(os.path.join('data', 'eq_data.csv'))
# Because dates are parsed as text by pandas
data.time = pd.to_datetime(data.time, format='%Y-%m-%dT%H:%M:%S.%f')
# The engine_name is mapped to an actual engine object via dict lookup
data.to_sql('earthquakes', con=DB_ENGINES[self.engine_name], if_exists='replace', index=False)
The engine_name Parameter has a default value, and can be omitted when using the Task. It will then be set to the default value. The run() method sends data from a csv file to the database. Luigi will then check whether the table exists by using the SQLiteTableTarget object.
Furthermore, the requires() method returns another Task, meaning that luigi will wait for this other Task to complete before starting this one.
Now that we have data in our database, we can implement the Tasks necessary to run the queries and create the reports. The Task running a query is presented here below. This Task takes two Parameters: the file name of the query that will be run and an engine name.
///code: le_export_data.py
from le_fetch_data import *
import luigi
import pandas as pd
import os
class ExportDataBasedOnQueryFile(luigi.Task):
query_file_name = luigi.Parameter()
engine_name = luigi.Parameter(default='eq')
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.query_path = os.path.join(QUERIES_FOLDER, self.engine_name, self.query_file_name)
#Get name of the file with extension
_, self.input_query_file = os.path.split(self.query_path)
#Get name of the file, without extension
self.output_filename, _ = os.path.splitext(self.input_query_file)
self.complete_filename = '{db_source}_{output_name}.xlsx'.format(db_source=self.engine_name,
output_name=self.output_filename)
def output(self):
return luigi.LocalTarget(os.path.join(OUTPUT_FOLDER,
self.complete_filename))
def requires(self):
return GetEQData()
def run(self):
if not os.path.isdir(OUTPUT_FOLDER):
os.mkdir(OUTPUT_FOLDER)
with open(self.query_path, 'r') as query_file_handle:
query = query_file_handle.read()
extracted_data=pd.read_sql(query, con=DB_ENGINES[self.engine_name])
extracted_data.to_excel(os.path.join(OUTPUT_FOLDER, self.complete_filename), index=False)
In the __init__() method, a query_file_name is decomposed into two parts: the file name and its extension. The engine_name is used later as a mapping to the engine objects, and to identify the origin of each report. In the run() method, we extract the content of the query file and run it against the database using pandas. The extracted content is then used to create an Excel file, which will be put in the desired folder.
We can then use this ExportDataBasedOnQueryFile Task in a WrapperTask that will iterate over the query files located in a directory:
///code: le_export_data.py
class ExportQueriesInFolder(luigi.WrapperTask):
folder_name = luigi.Parameter(default='eq')
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def requires(self):
if self.folder_name in DB_ENGINES:
files = os.listdir(os.path.join(QUERIES_FOLDER, self.folder_name))
sql_files = [file for file in files if os.path.splitext(file)[1] == '.sql']
return [
ExportDataBasedOnQueryFile(query_file_name=sql_file, engine_name=self.folder_name)
for sql_file in sql_files
]
The requires() method of this Task will search the folder called folder_name and for every SQL file it finds, it will produce an ExportDataBasedOnQueryFile with two Parameters: the file name and the folder name. This is then mapped to the engine that will be used to run the query via the DB_ENGINES dictionary.
The last Task is again a WrapperTask that will iterate over all the directories in the ‘queries’ directory. It will check if their name is in the DB_ENGINES dictionary and if so, it will produce an ExportQueriesInFolder Task with the name of that directory as a Parameter.
///code: le_export_data.py
class ExportAllQueries(luigi.WrapperTask):
def requires(self):
folders = [
folder for folder in os.listdir(os.path.join(QUERIES_FOLDER))
if folder in DB_ENGINES
]
return [ExportQueriesInFolder(folder_name=folder) for folder in folders]
Next, we wrap everything up into a MainTask: triggering the pipeline via a command-line command or the execution of the python script:
///code: le_main.py
import luigi
from eq_extract_data import *
class MainTask(luigi.WrapperTask):
def requires(self):
return ExportAllQueries()
if __name__ == '__main__':
luigi.run(main_task_cls=MainTask,
local_scheduler=True)
Then, a number of SQL files are put in the ‘queries/eq’ directory, in order to produce the Excel reports:
///code: eq_per_state.sql
SELECT net as network,
count(*) as number_of_event
from earthquakes
group by net
///code: max_eq_per_day.sql
SELECT date(time) as date,
max(mag) as magnitude
from earthquakes
group by date(time)
The pipeline is then triggered from a terminal, after launching the Central Scheduler:
C:\KPN > luigid
C:\KPN > python le_main.py
Luigi should run all the Tasks in the schedule (this should go relatively quickly). You can then access the Central Scheduler at the following address: http://localhost:8082, and you should see the list of Task that have been run at that moment, along with their status.
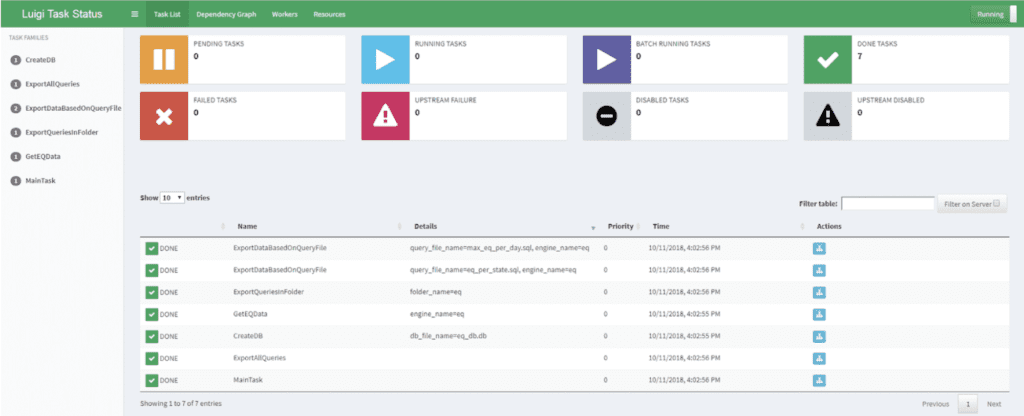
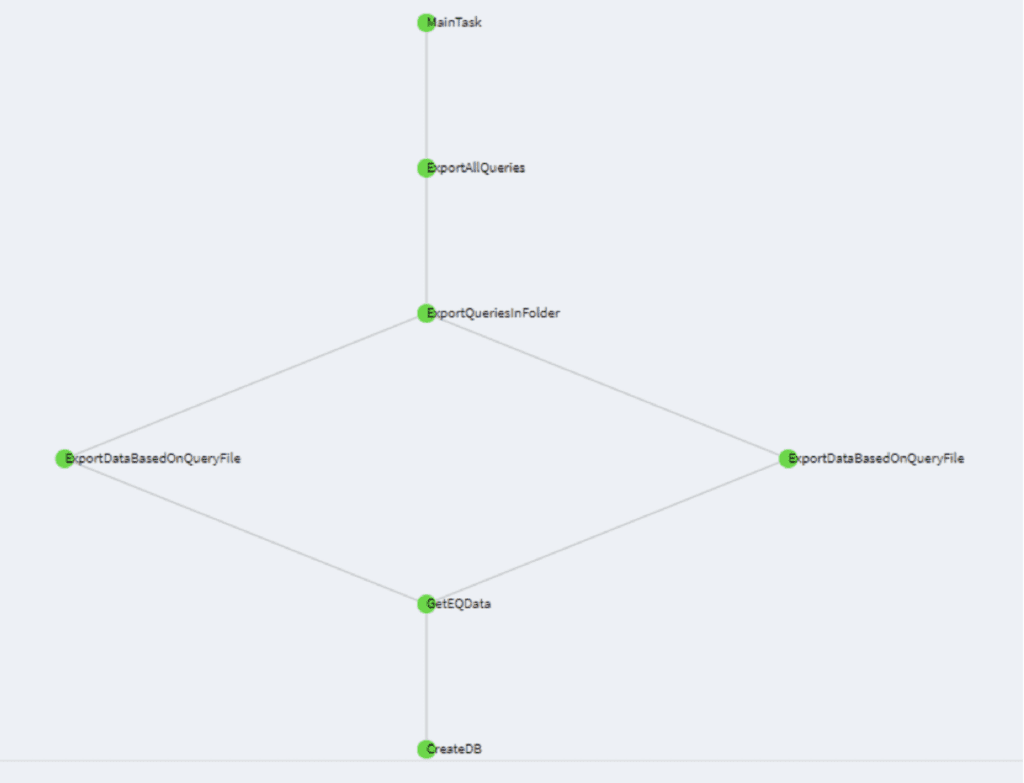
Now, have a look in your results folder. There should be two Excel files. Congratulations! You have set up your first luigi pipeline!
We learned how to implement a luigi pipeline that dynamically produced Tasks based on SQL queries coming from a folder. Normally, you should be able to drop other SQL files in the ad hoc directory and get an Excel output after running luigi. In conclusion, here are a few tips on how to implement your own luigi pipeline:
Luigi has been built with the idea that Targets should represent your actual inputs and outputs. Therefore, if a Task needs a csv file produced by another one, make sure the Tasks producing the csv file have an output() method returning that csv file.
Luigi was built with Task failure in mind, and numerous aspects of the framework revolve around controlling, preventing, and warning developers when a failure occurs. Tasks allow you to implement the on_failure() method, which will be executed if a Task fails. The configuration file can be used to define an email address to send messages to in case of Task failure, along with related stack trace. Tasks also provide a way to add other email recipients via the owner_email property. Third party libraries integrate with Slack and other tools. Furthermore, when a Task fails and you fix it and rerun your workflow, luigi will pick things up right where it stopped.
In case Parameters have to be passed on from Task to Task, Tasks implement a clone(OtherTask) method that can be used in the requires() method. This results in the instantiation of another Task with the same Parameters value. This gets really useful when a lot of Parameters must be passed on to dependencies.
Luigi is great and can accommodate for a lot of different Tasks and jobs. However, triggering is not built into the library. Therefore, you have to rely on other tools to (i.e. cron or bash scripts) or manually start the workflow in order to run it.
As seen during the tutorial, luigi comes with a built-in scheduler, linked to a great web interface that can easily show the current running Tasks and their associated Parameters, the status of the whole pipeline and the history of the different Tasks. It is also possible for a Task to send messages to be displayed by the scheduler, via the set_status_message() method. A completion bar can also be displayed using the set_progress_percentage() method. However, these methods will fail if the central scheduler is not used.