CopernNet : Point Cloud Segmentation using ActiveSampling Transformers
In the dynamic field of railway maintenance, accurate data is critical. From ensuring the health of ...


Published on: August 17, 2021
DevOps is a set of practices, automated processes and tools that allows both developers and operations professionals to work cohesively to build and deploy code to a production environment, to enable continuous delivery of value to the end customer.
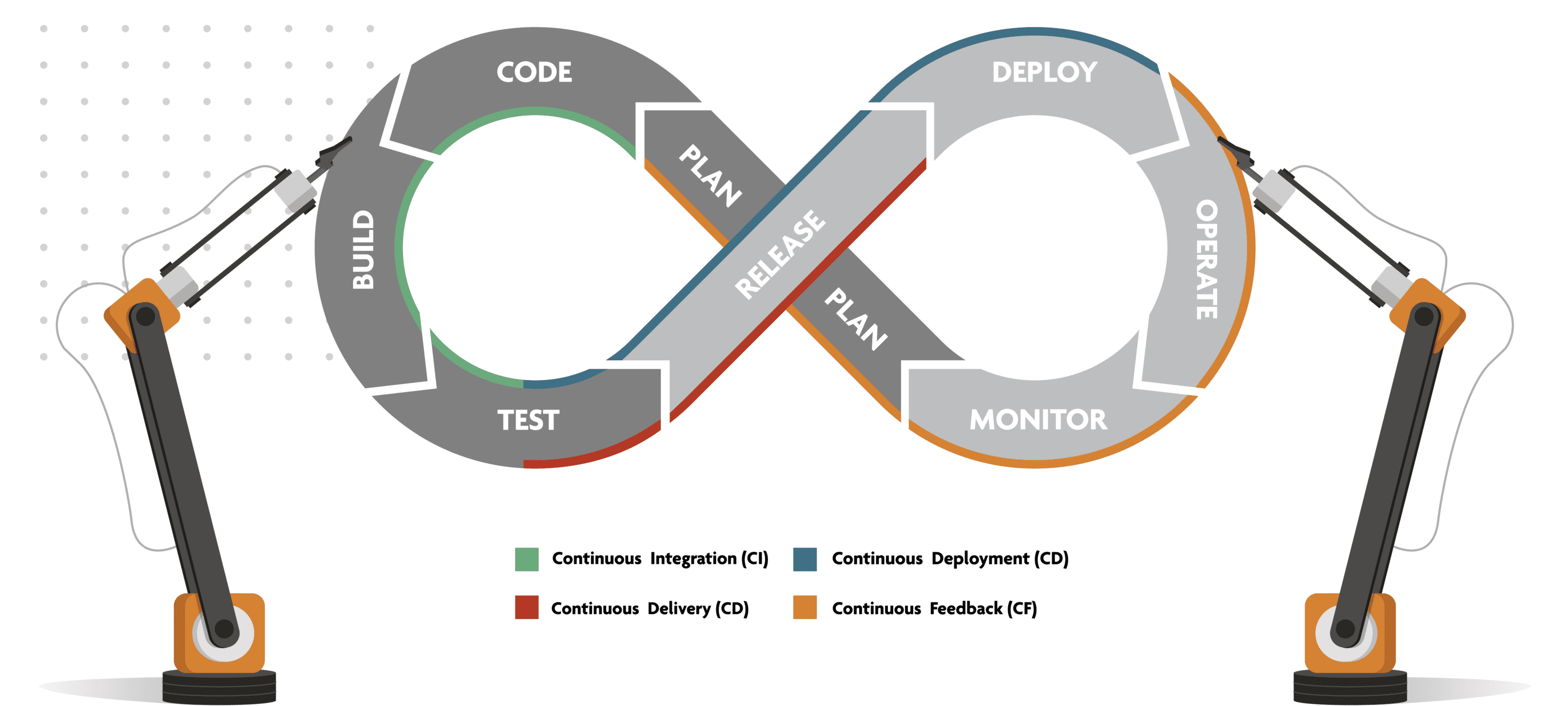
Continuity is a fundamental characteristic of a DevOps process. It includes continuous integration, continuous delivery/deployment (CI/CD), continuous feedback and continuous operations. Instead of one-off tests or scheduled deployments, each function occurs on an ongoing basis. Both development and testing activities are concurrent. That is also why the Agile Methodology works well in tandem with DevOps: it encourages continuous alignment between the development process and customers’ needs. This is in stark contrast to the Waterfall Model, which relies heavily on stable and well-known requirements. As we’ll see further on, automation plays an important role in enabling these continuous processes.
How does a DevOps process work and what does it look like? We will break the continuous process down in eight phases and look at each one from a little bit closer. We can then focus on the tools and processes in each phase and see what best practices look like. There is no single, standard DevOps process: many organizations follow similar methodologies but they may use different terms, cut the process in different places or do things in a slightly different order. Different technology stacks can also impact the process.
Agile software development is an approach under which requirements and solutions evolve through the collaborative effort of self-organizing and cross-functional teams with their customers and end users. It advocates adaptive planning, evolutionary development, empirical knowledge, and continual improvement. It encourages rapid and flexible response to change. Example methodologies are Scrum and Kanban.
The planning phase precedes any coding. Requirements and feedback from stakeholders are used to build and update a product roadmap, to guide future development. This product roadmap can be broken down in epics, features and user stories, creating a backlog of tasks.
Since the DevOps process seeks to deliver value continuously and incrementally over short development cycles, we prioritize and focus on delivering relevant and functional software to the users at the end of each cycle. Tasks are sized and allotted to the development team from the backlog.
In a mature DevOps process, the planning phase is about selecting and prioritizing what to work on next. We avoid writing up detailed requirements in advance which would then require formal changes over multiple cycles. Ideally, the implementation details are the result of the continuous collaboration of a cross-team during coding and testing, which shortens the lead time considerably.
Non-functional requirements (NFRs) should be defined as early as possible and should be an integral part of the development cycles. Security, for example, should not be treated as an afterthought or a segregated phase squeezed into the delivery phase.
The organization of the product roadmap and follow up on tasks, tickets and incidents are done in tools such as Jira and Azure DevOps Boards.
The next phases are also referred to as Continuous Integration. All modifications of the codebase are thoroughly and automatically checked against predefined minimal quality standards. We want to detect issues as early as possible. The result includes finished features and should lead to a stable and releasable product.
The developers work on the assigned tasks, modifying the codebase.
A lot of tooling, frameworks and best practices exist to increase both the quality of the code and the efficiency of the developer, decrease the manual efforts, speed up the development process and make it less prone to error.
We focus on writing functional code that is elegant, but simple and easy to maintain. Developers work in dev environments and use IDEs, sandboxes, containers, linters and automated testing, allowing for fast feedback cycles. Adhering to frameworks and code-styling standards improves collaboration and consistency.
The developer also writes unit tests and documentation during this phase when everything is still fresh in his mind.
It is also very important to include security as early as possible in the development cycle, to avoid having to apply security hardening with brute force later.
Writing software is usually a collaboration of many developers, who are often working in remote locations. When a developer finishes a task, he needs to commit his code back to the shared code base. The developer submits a pull request – a request to merge his new code with the shared code repository – the start of the actual build.
In the build phase, the code base is compiled or packaged, producing artifacts – executables, libraries, packages, container images, DACPACs, scripts and more – that can be deployed to production. This process includes a series of automated code quality checks and tests, and may include a number of manual approval gates – for example a code review.
The whole process can be automated by using tools like Jenkins or Azure DevOps pipelines.
The master code is kept functional at all times. If any issues are encountered, the build process is halted and the merge is rejected. The developer is notified to resolve the issue.
In a classic waterfall project, testing is a completely separate step, executed by a separate team with a lot of manual effort. In a mature DevOps process however, there are no silos between developers and QA. Testing is done continuously and is automated as much as possible .
A testing suite consists of different levels of granularity, covering all layers of the application. Isolated tests such as unit and contract tests can and should be executed during the Build. Higher level tests such as integration and end-to-end tests span across multiple build artifacts or external systems.
Beyond using stubs to mock dependencies and other components of the system, we can also deploy the artifacts to a dedicated testing environment, which is set up to be as production-like as possible for deeper, out-of-band testing. By using a test bed, there is no interference with the flow of the developers or impact on the production environment.
Manual user acceptance testing is increasingly being automated as well with DevOps maturity. Modern tools have built-in record-playback-verification mechanisms to execute visual testing that are accessible to its users and require little maintenance or configuration.
Performance testing provides valuable information on the scalability, stability and reliability of the application.
Security testing uncovers vulnerabilities, threats and risks in a software application and prevents malicious attacks from intruders.
Some tests are not executed on a testing environment but directly on the production environment itself, using feature flags. The new code is deployed to the production environment, but the new features can be enabled for test users or for a limited number of end users only.
The test phase is also a rehearsal for the deployment to production, as it includes testing of the infrastructure provisioning and of the deployment of the artifacts. The idea is to use infrastructure-as-code and pipelines-as-code which are completely independent of the target environment. Testing these automated processes with different configurations against different environments will give confidence towards a completely automated deployment to production.
While Test is a distinct phase, it is actually a continual part of the entire cycle. Organizations should constantly be validating ideas, deployments, user experience, and features throughout the entire cycle in order to get rapid and continuous feedback. This will improve the entire cycle and experience.
A milestone is reached in the DevOps process: each code change has now been integrated and tested. The Build artifacts are ready for deployment into the production environment.
The release management team is responsible for the release strategy, which determines how and when builds are released to production. Releases may follow a regular schedule or require extensive planning in terms of interdependencies, coordination with external parties, resource utilization and migrations. Release notes, release documentation and operational documentation are composed and communicated.
The classical formal hand-off between Dev and Ops loses meaning as the DevOps process matures and is fully automated. Each pull request to master for a new feature is built and tested automatically and deployed immediately to production. Some organizations manage to deploy multiple releases every day.
It’s D-Day: the build is released into production. Well, actually, our ideal DevOps process is continuous, so every day is D-Day.
Several tools and processes exist that can automate the release process to make releases reliable without outage window.
The deployment to production should be completely predictable, because we use the same process as when we deployed the build to the test environment(s) and configured it for the production environment. This is where automation and Everything-as-Code pays off big time.
The new build artifacts can be deployed to the existing production environment, migrating the infrastructure and software to the new release, or to a completely new production environment, or to a mix of both.
In a blue-green deployment, a new environment is built alongside the existing production environment. When ready, users and traffic are redirected to the new environment with no outage. If at any point an issue is found with the new environment, it is possible to roll back to the old environment.
Once the services or new features are live and are being used by the customers, the operations team makes sure that everything is running smoothly.
The resources in the environment are scaled automatically to handle peaks and troughs while system errors and network issues are resolved. This helps to automatically fix the problem as soon as it is detected.
Vital information of the service is being recorded and processed to recognize the proper functionality of the service. Metrics and logs are collected, categorized and analyzed to provide insight on customer experience, customer behavior, performance, compliance, errors, trends etc. Monitoring is usually integrated within the operational capabilities of the software application.
Channels for feedback from the users are put into place, integrating them with tooling to collect, triage and follow-up on them.
Apart from monitoring the software application, we also need control and visibility of the DevOps process itself, by collecting and instrumenting everything. We look for potential bottlenecks which are causing frustration or impacting the productivity of the development and operations teams.
Popular tools used for this are Splunk and the ELK Stack.
All of this information is then fed back to the Product Manager and the development team to close the loop of the process, helping shape the future development of the product and the DevOps process itself. It would be easy to say this is where the loop starts again, but the reality is that this process is continuous. There is no start or end, just the continuous evolution of a product throughout its lifespan, which only ends when people move on or don’t need it any more.
Subscribe to our newsletter and stay up to date.
