Interview with Frank Dekervel: Agentic AI, Applied
"Agentic AI turns the knowledge worker fro ...
Published on: June 27, 2018
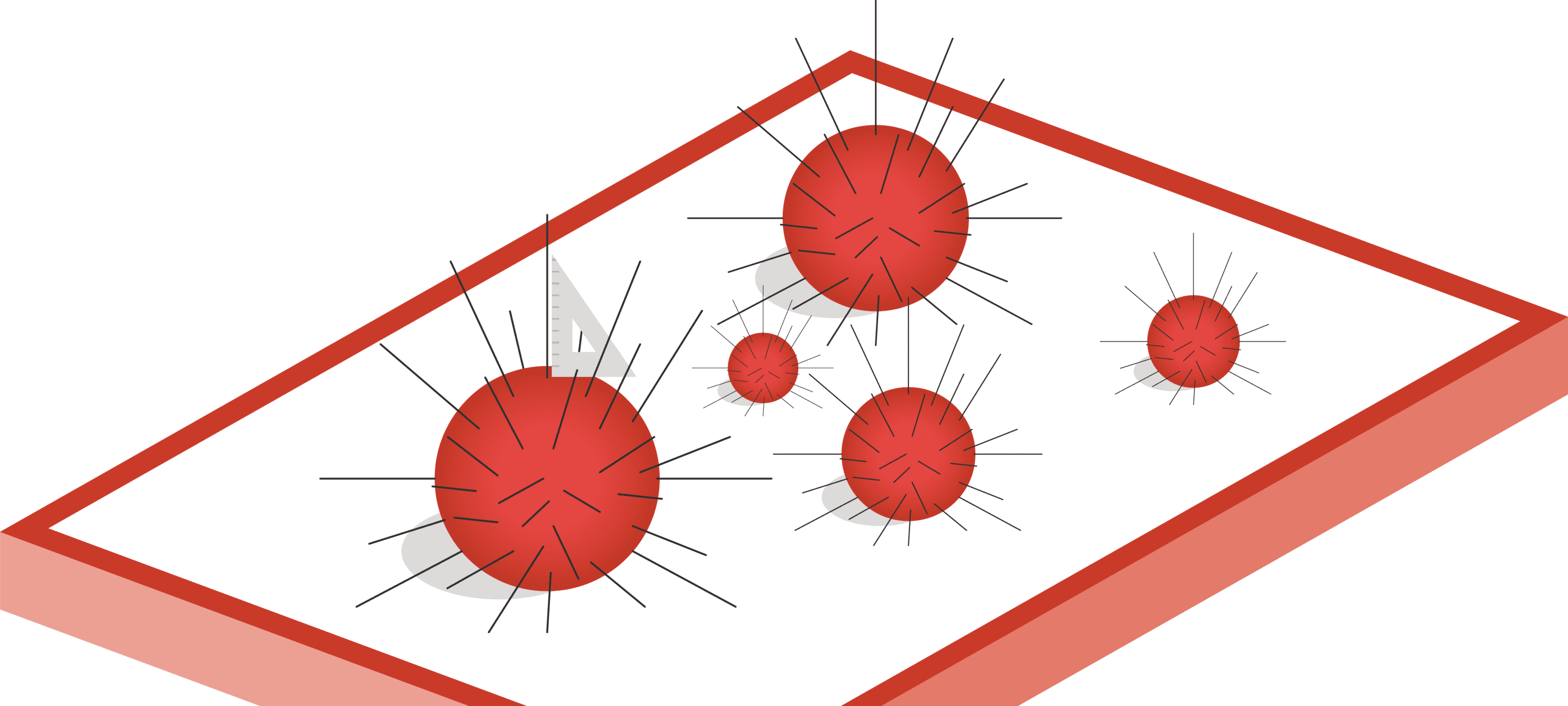
A step we often use when processing a point cloud for vision applications is a surface normal computation. Normals of a surface are able to better expose certain characteristics of that surface. For example, in the figure below, by considering the normals, it gets much easier to separate globular surfaces like the spheres from their surroundings. Other applications include flat shadowing¹.
Most frameworks for processing point clouds, like the Point Cloud Library (PCL), provide very convenient functionality for this computation. However, once we start scaling our point cloud, this step often becomes a performance bottleneck. As a regular developer, we seize this opportunity to offload the calculation to the GPU, as PCL supports this out of the box. Unfortunately, in between the magic incantations described on their page about GPU support², it is clearly stated that PCL only supports CUDA, a proprietary parallel computing framework from Nvidia, designed to work only with Nvidia devices. In a world that is increasingly trending towards integrated (non-Nvidia) GPUs, mobile devices and other graphic cards (e.g. from AMD), this is a disappointing discovery, as only gamers and cryptominers will be able to enjoy our smooth application.
Luckily, we do not have to waste the available computing power on those other devices: there is a more portable, widely supported, open standard available in the form of the Open Computing Language (OpenCL) framework. OpenCL is not limited to GPU devices, but can also offload to CPUs, FPGAs and custom accelerators. It is a standard that merely describes a generic interface for offloading computations to a co-processor; it is up to an external party, most often the device manufacturer, to provide a compatible implementation. The interface is built using task- and data-based parallelism principles³.

A considerable time of the normal computation is spent calculating the covariance matrix for all surfaces. It is very easy to rewrite this calculation as a series of simple vector operations for all these points at once. Boost.Compute is a wrapper around OpenCL that allows us to execute these vector operations using OpenCL without having to leave our CPU-centric comfort zone. Have a look at src/covariance_simd.cpp in the source code repository for an example of how the computeCovarianceMatrix() function from PCL can be rewritten for dense point clouds.
While this method is very convenient, it limits the amount of parallelism to the number of the points on a surface, which significantly limits the scalability and potential efficiency gains from this operation.
If we want to further improve our scalability and efficiency options, we will have to compute the normal of multiple surfaces in parallel, since big point clouds often contain a significant number of surfaces. However, this can no longer be done using the default operations included in Boost.Compute: we have to write our own OpenCL kernel. A kernel is a piece of code whose (still simple) operations are applied on every element of a one- or more-dimensional data structure. When data dependencies between separate elements are low, the kernel can be applied to multiple elements at once, resulting in a massively scalable algorithm. By using a kernel, OpenCL does the heavy lifting for us: it takes care of assigning the different elements to – potentially parallel – workers. These workers will apply the operations declared in the kernel to the element assigned to them. All we have left to do is write the actual kernel.
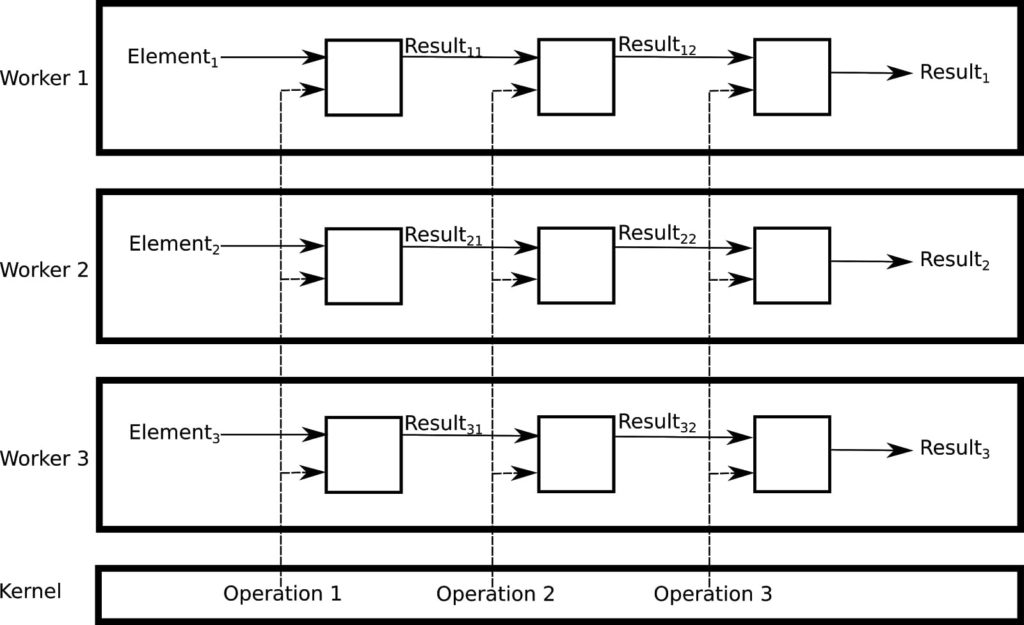
In point cloud normal computation, data dependencies between separate elements are not present: computation of the normals of one point is not influenced by the computed normals on the other points in the same point cloud. This allows us to write a kernel that performs the entire normal computation.
Next to the element on which the kernel is operating, additional, shared parameters can be passed to the kernel using function arguments. To avoid data races, each kernel will write its result to a separate index in the result vector.
Since all the input data is read-only and since the result vector exclusively reserves a memory location for the result, we can pretend that, within a worker thread, the code is executed as if it was running in a single-threaded application. As a result, the kernel code can be kept very similar to the original (single-threaded) CPU code. This means we can start from the original PCL implementation and make the following modifications:
In addition, the following adaptations must be made at the host in order to be able to call the OpenCL kernel:
The following systems were used for providing the benchmark results:
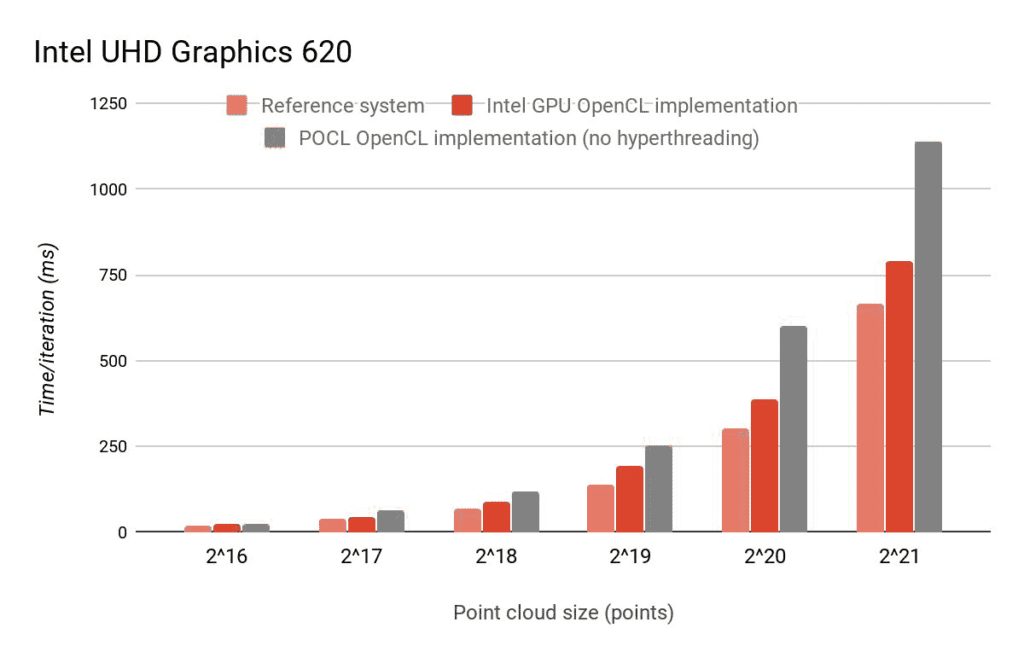
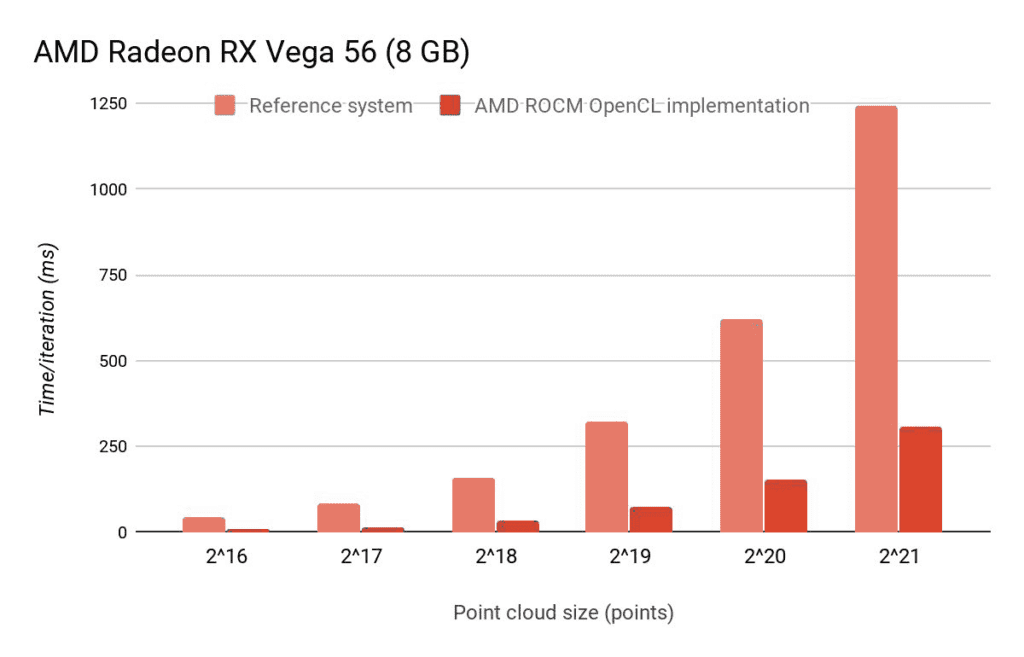
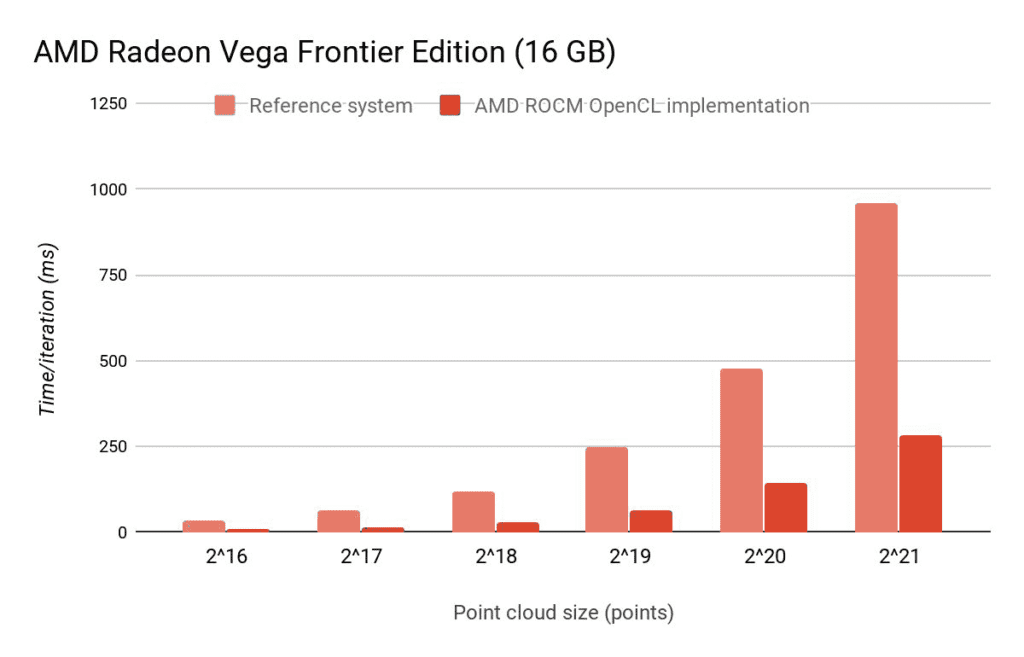
As we can see, on an integrated GPU, the OpenCL version is slightly slower than the CPU version. However, this does not mean it is useless: offloading these computations to the GPU enables the CPU to execute other work in parallel. Thanks to initiatives like the Portable Computing Language (POCL), which contains, next to some GPU backends, also a CPU-based openCL implementation, even the target-specific CPU parallelization options can be exploited without any additional effort.
We did not do any memory access tuning yet, and while the random access needed by the KNN lookups makes this difficult, improvements remain possible. In addition, the OpenCL kernel is still a rather straightforward mapping of the original CPU code. Further OpenCL- and/or GPU-specific optimizations can further improve the efficiency.
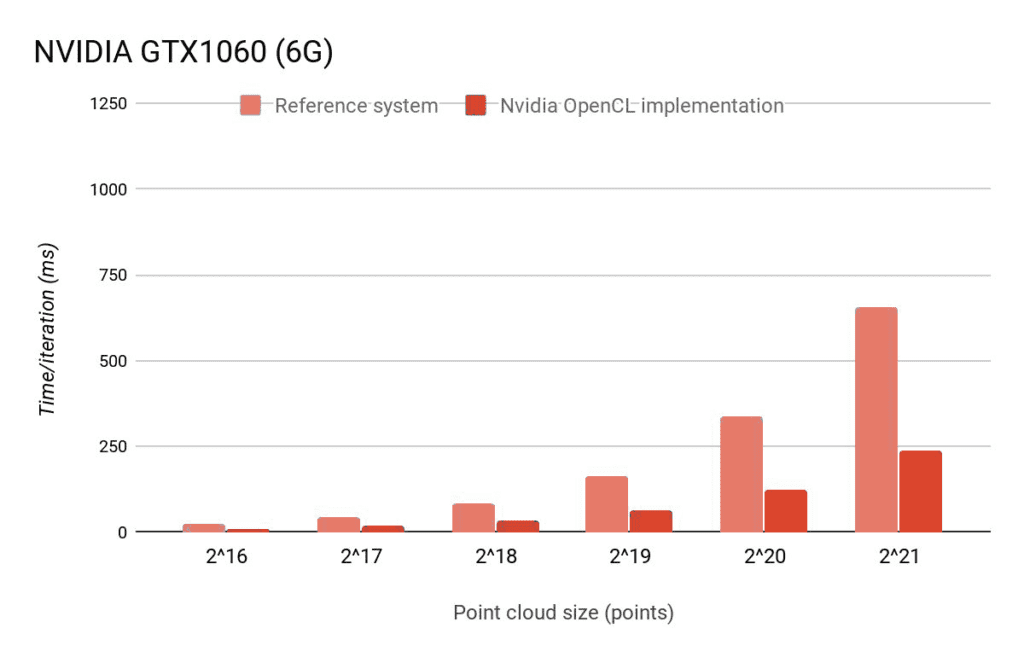
On a system with an Nvidia GPU, the OpenCL implementation becomes much faster than the CPU version. Of course, using the CUDA version might still be faster. Similar results for the OpenCL implementation can be observed on AMD GPU-based systems.
Full source code is available our Github.
Instructions for reproducing the results for your system can be found in the .gitlab-ci.yml file in the source code repository. Note that for portability reasons, the system uses the POCL library for enabling OpenCL. Vendor specific OpenCL implementations for your platform can be used instead by installing the associated packages. A great guide on enabling OpenCL on your platform can be found on the Arch Linux wiki. Note that package names may differ for your platform.