RINF 2026: What Railway Infrastructure Managers Need to Know
Visit our dedicated RINF roadmap site: roadmap2rinf.eu The European railway infrastructu ...
Published on: July 29, 2020
At Kapernikov, we have used multiple data processing frameworks over the years. Today, we want to refresh our knowledge of the available open source tools to know which one to choose to implement ETL and ELT in customer projects. We also want to look briefly at data processing for ML pipelines.
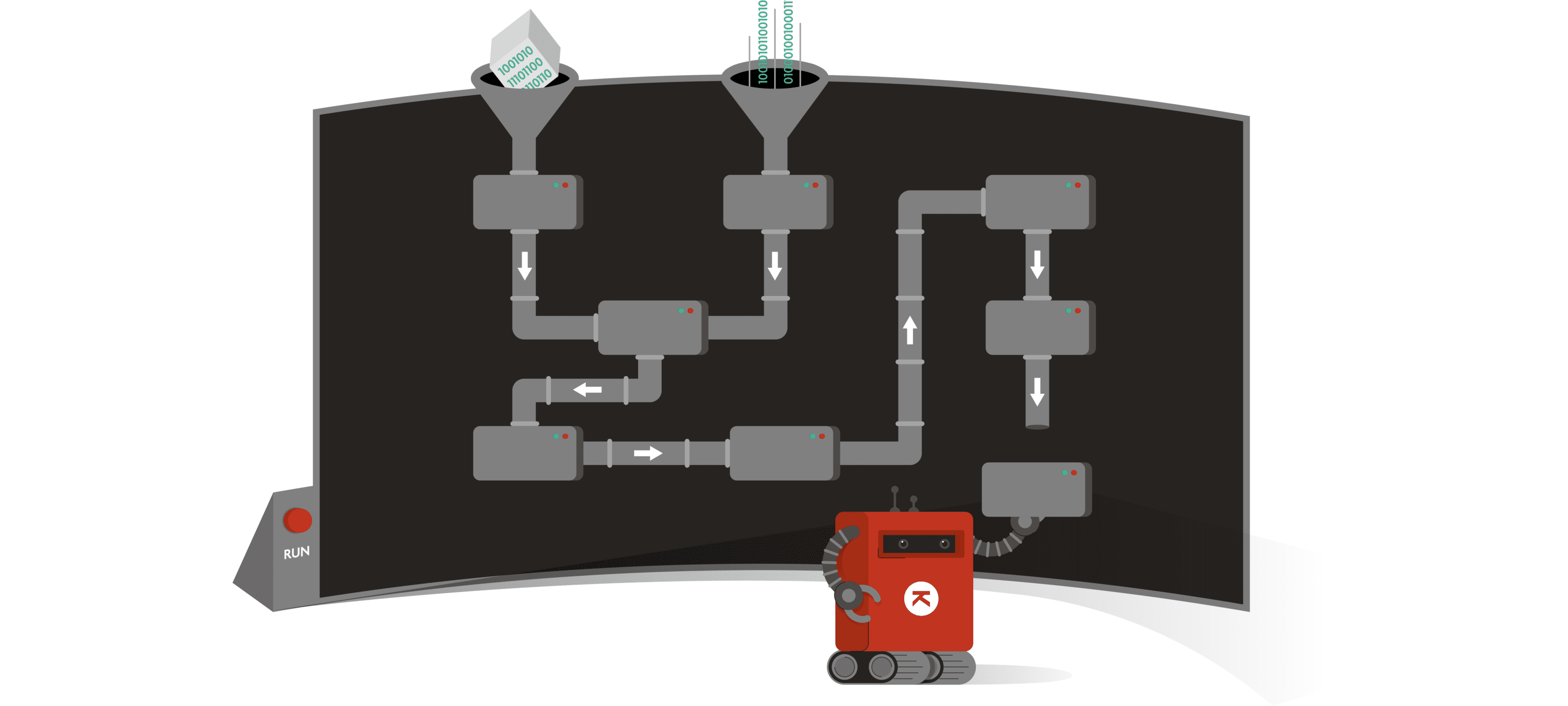
Data processing can be challenging, as sometimes it requires different execution environments and playing with different types of data. Orchestrating this data processing can be complex due to dependencies. Services, like streaming of data or predictive models in Machine Learning, are now also incorporated into data processing. And what role can Kubernetes play in an architecture for data processing?
In this article, we discuss these challenges. We start by defining the key components of a data processing framework. Then, we compare the different tools that exist today using a set of characteristics. Finally, we present some of them which we think are the best options for specific situations.
A data processing framework is a tool that manages the transformation of data, and it does that in multiple steps. Generally, these steps form a directed acyclic graph (DAG). In the following report, we refer to it as a pipeline (also called a workflow, a dataflow, a flow, a long ETL or ELT).
The steps are units of work, in other words: tasks. Each task consumes inputs and produces outputs. These data artifacts can be files, in-memory data structures but also ephemeral services. The data can be structured or unstructured. And the services can be streaming services that continuously deliver new data or predictive models that are used in tasks.
The pipeline is controlled by an orchestrator which ensures its correct execution. This orchestrator can be decomposed in three components:
Generally, the three components are managed internally by the framework and the end user doesn’t need to control them directly. With the Kubernetes¹ platform, some solutions make use of the Kubernetes API to create their own orchestrator which is called a “Kubernetes operator”. These orchestrators are defined natively in Kubernetes using custom resource definitions (CRD).
¹ Kubernetes (K8s) is a fully customizable platform for orchestration of containers. It is becoming a standard in its domain. It is therefore not surprising that most of the tools presented in this article have a way to connect to Kubernetes.
In this way, these frameworks delegate their task processing to a robust and well supported platform and they can focus on the specifics of the management of data pipelines.
Note that the frameworks that we will compare generally allow to implement pipelines following the functional data engineering principles, and remember that we have also exposed our best practices when building pipelines at Kapernikov.
There are a lot of data processing frameworks. Here, we are only looking at code based frameworks and we are not presenting an exhaustive list. But we can classify them using three important features that interest us:
Task-driven frameworks are highly decoupling the task management from the task processing. Therefore, they have limited to no knowledge of the content of the task processing. They are pure workflow tools that can be used for any workflow of tasks, not only data processing.
On the other hand, data-driven frameworks know the type of data that will be transformed and how they will be transformed. They have a greater data awareness, are type-safe and can perform tests on data artifacts. Not only versioning of the code, but also versioning of the data artifacts is possible. They can also make use of caching or reuse of computation to increase efficiency (Incremental computing).
Some frameworks only do batch processing or streaming processing. Others do both.
We refer to fine-grained or coarse-grained to distinguish the level of granularity of the data processing. Fine-grained frameworks manipulate low-level data structures (arrays, classes…) directly whereas coarse-grained frameworks manipulate batches of higher level data structures (tables, models, graphs…).
Well used fine-grained frameworks are for example: Dask, Apache Spark and Apache Flink. All three are data-driven and can perform batch or stream processing. They can also run in Kubernetes. They can be very useful and efficient in big data projects, but they need a lot more development to run pipelines.
Common coarse-grained frameworks are the following:
† Dagster is not yet ready for incremental computing but has started to implement it.
° Luigi supports persisting output caching based on file targets.
* Prefect has persisting output caching between tasks and pipelines and seems open to implement streaming.
Except for specific needs, we generally want to start with coarse-grained frameworks. So, let’s focus on them and compare them around more features:
| Frameworks | Distributed tasks | Parallel tasks | Integrations | Maturity | Pipeline definition | Kubernetes orchestration |
| Airflow | Using Celery or Kubernetes | Using Celery or Kubernetes | Dask | Mature | Pipeline-as-code* (Python) | yes |
| Dagster | Using Celery [ref] or Dask | Using Celery [ref] or Dask | Spark, Airflow, Dask | New | Pipeline-as-code (Python) | yes |
| Prefect | Using Dask [ref, ref] | Using Dask [ref, ref] | / | (unclear) | Pipeline-as-code (Python) | yes |
| Luigi | no | yes | Spark | Mature | Pipeline-as-code (Python) | / |
| Reflow | yes | yes | / | (unclear) | Pipeline-as-code (Python) | / |
| Argo Workflow | Using Kubernetes | Using Kubernetes | Airflow | (unclear) | Typed declarative schema | Natively using CRD |
| Koalja | Using Kubernetes | Using Kubernetes | / | New | Typed declarative schema | Natively using CRD |
Integrations:
Integration to other frameworks.
Pipeline definition:
Is the pipeline definition decoupled from the framework? With pipeline-as-code, it is not the case. The definitions of the pipelines are written in code by calling objects from the frameworks library, like Task and Dag objects.
With typed declarative schema, framework and pipelines are completely separated. It means that the definition is stored in a file type similar to YAML files where description of the pipelines is given.
With pipeline-as-code, you can generate pipelines dynamically, which is not possible with typed declarative schema, or at least less flexible.
Kubernetes orchestration:
Inform if the framework can do its orchestration using a Kubernetes cluster. This means managing pods by itself and executing every task inside the cluster. Note that Luigi can only run specific tasks inside the cluster while running other tasks from outside of the cluster [ref].
*Also typed declarative schema using an external library
This table does not reflect the full situation. We have additional comments on some tools.
Koalja is based on Koji, which is described in this article. This article is very interesting as it presents an overview of data processing frameworks and why Koji was created. One important new feature of this framework is what they call the causal caching. They describe it as an extension of the content hashing but working also for services. It enables persisting caching of data artifacts between different DAG’s. One consequence is that a huge DAG could be split into smaller ones to simplify the management without losing efficiency. The other new implementation is that it manages services in the pipelines.
Specifically Koalja is a layer on top of Koji that make the K8s context transparent for the end user. It is still a young framework and not broadly used. However, its new features are interesting to keep in mind.
Luigi is not receiving a lot of new exciting features recently, but it is still regularly maintained for bug fixing and small features. Note that Kubernetes jobs are possible using a contributed module.
GoKart is a wrapper around Luigi that makes it easier to define pipelines. It simplifies the Luigi target (output of tasks) management and provides more logging information. There is also a cookiecutter template for it and some advanced examples to perform ML with it.
Finally, there is d6tflow, which is another wrapper around Luigi claiming to be more suited for ML workflow.
To wrap-up this article, we want to give more insight on what to choose. Note that it can heavily depend on the details of projects.
Dagster has an important data awareness. Schemas for data artifacts can be defined, which enables type checking. So, even if the framework has regularly breaking changes, the benefits of using it could be important. Moreover, you can still use Airflow operators to have access to a lot of execution environments and Spark, Dask to create more fine-grained tasks.
If data awareness is not important in the pipeline itself, Airflow is still a big player. In fact, Airflow works very well when the data awareness is kept in the source systems, e.g. databases. Moderns db’s are obviously highly aware of the data content. They are data-driven, have some knowledge on the data and make extensive use of query plan optimization and caching. Used with tools like dbt, you can also get the data lineage of the data, starting from when it entered the database.
In the case you need streaming along batch processing in your pipeline, you do not have that many options. Either you take time for development using a fine-grained framework with the advantage of using mature frameworks. Or you try the new Koalja which is natively implemented on K8s and have an interesting incremental data processing engine.
However, if your pipeline is to be event-driven only, you should probably head to a real-time data processing engine such as Kafka Streams API or its alternatives Apache Samza and Apache Storm.
Don’t rush blindly into streaming systems though: if your requirements are only near-realtime (e.g. updates every 5 minutes or so), there is a big chance you can still use the “good old” batch processing with mini batches.
When the pipeline needs to be robust, a good option could be to use a solution that relies natively on Kubernetes. In this case, your containerized pipeline benefits from the robustness of this well supported platform, and your framework focuses only on the management of the pipelines.
There are a lot of ML-specific frameworks. Kubeflow pipelines, MLFlow and Metaflow are open-source; others are partly open-source, such as Pachyderm and Polyaxon. A lot of them are implemented natively in Kubernetes and manage versioning of the data. Note that Pachyderm supports streaming, file-based incremental processing and that the ML library TensorFlow uses Airflow, Kubeflow or Apache Beam (Layer on top of engines: Spark, Flink…) when orchestration between tasks is needed.
If you already use data processing frameworks for ETL extensively, and you feel that these offer possibilities for ML pipelines (cf. Luigi and co), it is probably nice to invest a little bit of time to obtain or prepare simple templates for ML with these frameworks.
Fully customized workspaces for ML are probably also efficient and the open-sources ones seem to already have a lot of the features that the freemium ones have.
Look out for our upcoming article on Data Warehouse automation software. Do they keep their promise of alleviating the repetitive work in writing data pipelines? And which tool to choose for which situation?