

Streamline your operations
DevOps is a set of practices that aims at improving the speed and quality of your software development cycle. DevOps focuses on automated processes and tools that allow your development team and operational team to work together. With GitOps and DataOps, the DevOps principles have also been applied to version management and data analysis teams. Kapernikov can help you to set up your entire DevOps flow with your team so you can streamline operations and increase customer value.
We can help you to:
- Bring your development and operation teams together to show them the advantages of continuous delivery
- Implement the tools required for continuous delivery and DevOps
- Upskill your team on DevOps best practices
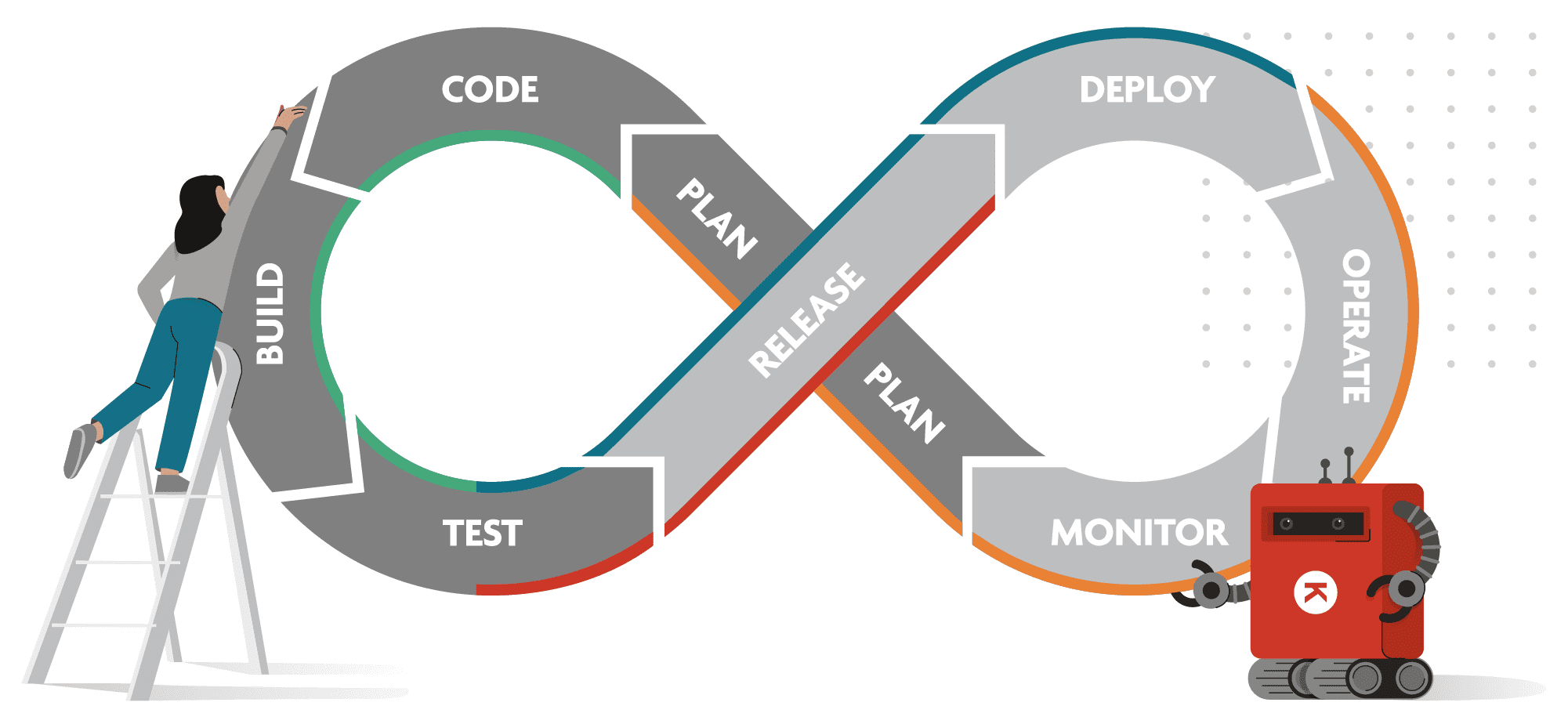
DevOps: continuous integration, continuous delivery
DevOps is a development philosophy that focuses on collaboration between operations and development teams to come to better results. DevOps works with a never-ending, iterative loop through which engineering teams can continuously improve. This is also called the CI/CD (continuous integration / continuous delivery) pipeline and it’s one of the best practices to implement and deliver code changes more frequently and reliably.
GitOps: single source of truth
Version control is essential for writing software, even if your software team only consists of one developer. But in an environment of continuous delivery, things can quickly become complex.
Applying GitOps principles means that teams are managing and reviewing the resources and configuration requirements of each application based on a single source of correct information. GitOps helps teams to track changes and modifications, and keep a central repository and version control for source code, configuration instructions, and operating parameters.
DataOps: streamlined data analysis
DataOps applies the DevOps principles and methodologies to the field of data analysis and data science. By applying DataOps, you want to reduce the time to create and deploy data pipelines, produce a greater output and higher quality of datasets, and achieve more reliable, predictable data delivery.